suppressMessages(library(tidyverse))suppressMessages(library(glue))PRE ="/Users/sgona/Library/CloudStorage/Box-Box/imlab-data/data-Github/Daily-Blog-Sai"## COPY THE DATE AND SLUG fields FROM THE HEADERSLUG="erap2-fine-mapping"## copy the slug from the headerbDATE='2023-03-28'## copy the date from the blog's header hereDATA =glue("{PRE}/{bDATE}-{SLUG}")if(!file.exists(DATA)) system(glue::glue("mkdir {DATA}"))WORK=DATA
Context
Am going to refocus on ERAP2 again for a few reasons:
1.) It is interesting
2.) I didn’t reevaluate the results after fixing some pipeline bugs
3.) It is a chance to implement personalized mutagenesis and compare with reference mutagenesis
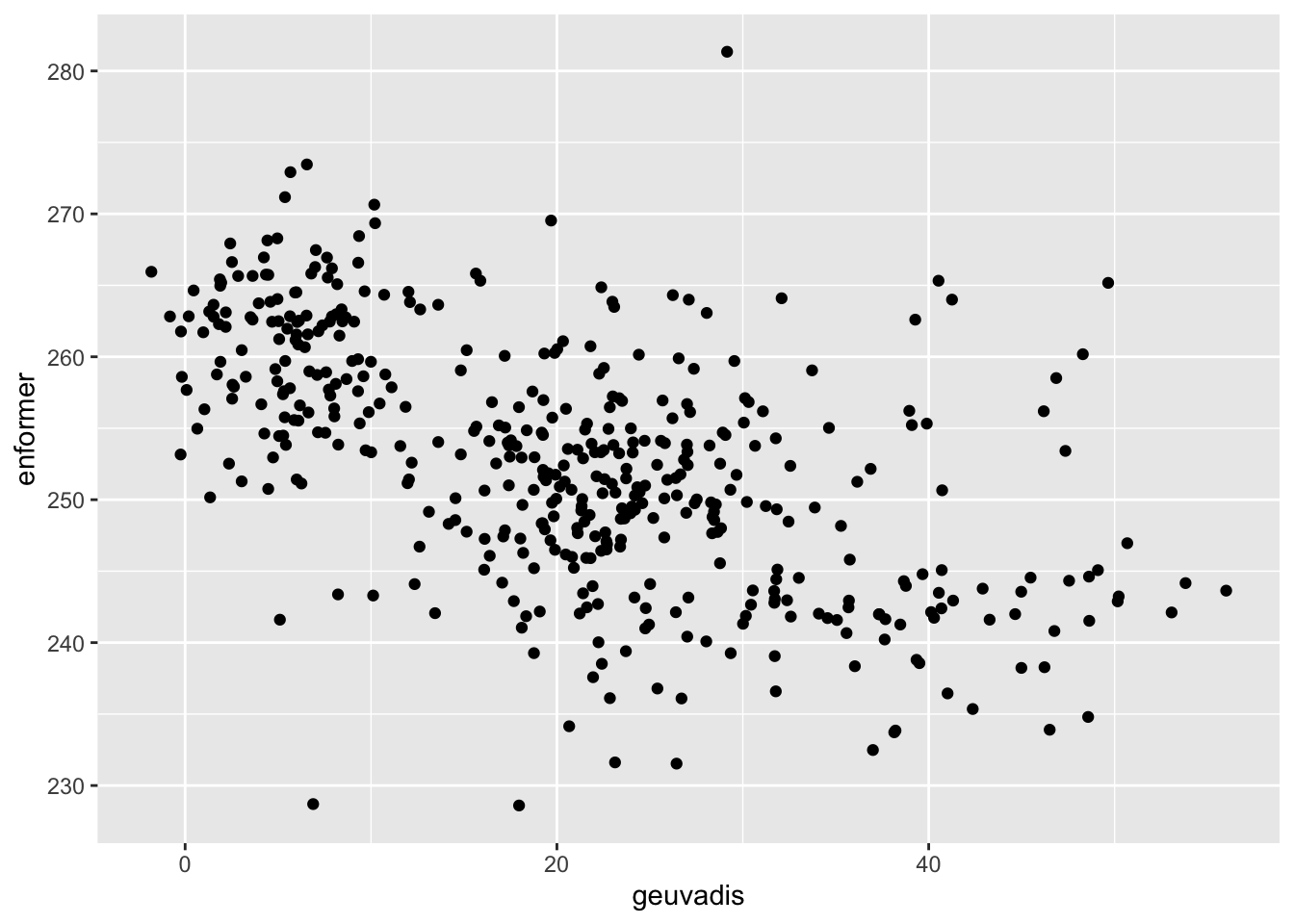
Great, the negative correlation clearly still holds.
Now we want to perform two types of mutagenesis for the ERAP2 region. The first is standard reference-based mutation, where each ERAP2 mutant of interest is mutated against a background of reference sequence. The second is individulized mutagenesis in which the mutations are done with different individualized background context.
The generation of the individualized mutagenesis is done in an ipython notebook on grand. Will document the contents next week.
Source Code
---title: "erap2-fine-mapping"author: "Saideep Gona"date: "2023-03-28"format: html: code-fold: true code-summary: "Show the code"execute: freeze: true warning: false---```{r}#| label: Set up box storage directorysuppressMessages(library(tidyverse))suppressMessages(library(glue))PRE ="/Users/sgona/Library/CloudStorage/Box-Box/imlab-data/data-Github/Daily-Blog-Sai"## COPY THE DATE AND SLUG fields FROM THE HEADERSLUG="erap2-fine-mapping"## copy the slug from the headerbDATE='2023-03-28'## copy the date from the blog's header hereDATA =glue("{PRE}/{bDATE}-{SLUG}")if(!file.exists(DATA)) system(glue::glue("mkdir {DATA}"))WORK=DATA```# ContextAm going to refocus on ERAP2 again for a few reasons:1.) It is interesting2.) I didn't reevaluate the results after fixing some pipeline bugs3.) It is a chance to implement personalized mutagenesis and compare with reference mutagenesis### Replotting of ERAP2 association```{r}library(tidyverse)library(ggplot2)dset_dir <-file.path("/Users/sgona/Library/CloudStorage/Box-Box/imlab-data/data-Github/analysis-Sai/enformer_geuvadis/enformer_portability_analysis")geuvadis_full <-read_delim(file.path(dset_dir,"GD462.GeneQuantRPKM.50FN.samplename.resk10.txt"))geuvadis_genes_symbols <-sapply(str_split(geuvadis_full$Gene_Symbol, "\\."),`[`,1)geuvadis <-as.data.frame(geuvadis_full[,5:ncol(geuvadis_full)])rownames(geuvadis) <- geuvadis_genes_symbolsenformer_haplo1 <-read.csv2(file.path(dset_dir,"CAGE_lcl_enformer_geuvadis_summed_haplo1_filtered.csv"), header =TRUE, row.names =1)enformer_haplo2 <-read.csv2(file.path(dset_dir,"CAGE_lcl_enformer_geuvadis_summed_haplo2_filtered.csv"), header =TRUE, row.names =1)enf_genes_symbols <-sapply(str_split(rownames(enformer_haplo1), "\\."),`[`,1)enformer <- (enformer_haplo1 + enformer_haplo2)rownames(enformer) <- enf_genes_symbolsge_inds <-intersect(colnames(geuvadis), colnames(enformer))enformer <- enformer[,ge_inds]geuvadis <- geuvadis[,ge_inds]ERAP2_df <-data.frame(enformer=as.numeric(enformer["ENSG00000164308",]), geuvadis=as.numeric(geuvadis["ENSG00000164308",]))ggplot(ERAP2_df) +geom_point(aes(x=geuvadis,y=enformer))```Great, the negative correlation clearly still holds.Now we want to perform two types of mutagenesis for the ERAP2 region. The first is standard reference-based mutation, where each ERAP2 mutant of interest is mutated against a background of reference sequence. The second is individulized mutagenesis in which the mutations are done with different individualized background context.The generation of the individualized mutagenesis is done in an ipython notebook on grand. Will document the contents next week.