RefToAracenaCNN(
(model): Sequential(
(0): Sequential(
(0): BatchNorm1d(1, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(1): GELU()
(2): Conv1d(1, 24, kernel_size=(4,), stride=(2,), padding=(1,))
(3): BatchNorm1d(24, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(4): GELU()
(5): Conv1d(24, 24, kernel_size=(4,), stride=(2,), padding=(1,))
(6): BatchNorm1d(24, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(7): GELU()
(8): Conv1d(24, 24, kernel_size=(4,), stride=(2,), padding=(1,))
)
(1): Sequential(
(0): Flatten(start_dim=1, end_dim=-1)
(1): Linear(in_features=2688, out_features=896, bias=True)
(2): Softplus(beta=1, threshold=20)
(3): Unflatten(dim=1, unflattened_size=(1, 896))
)
)
)
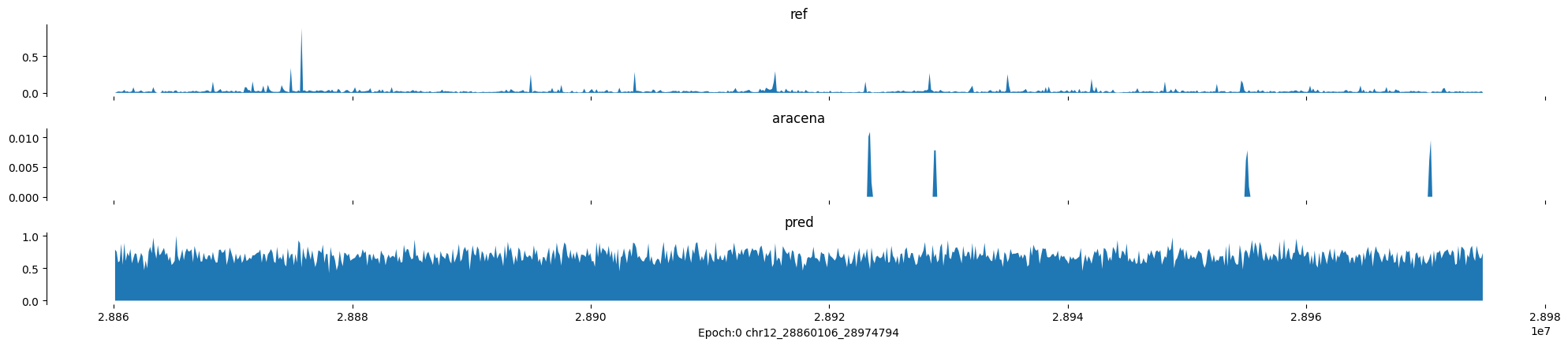
Epoch: 0
0
chr12:28860106-28974794:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
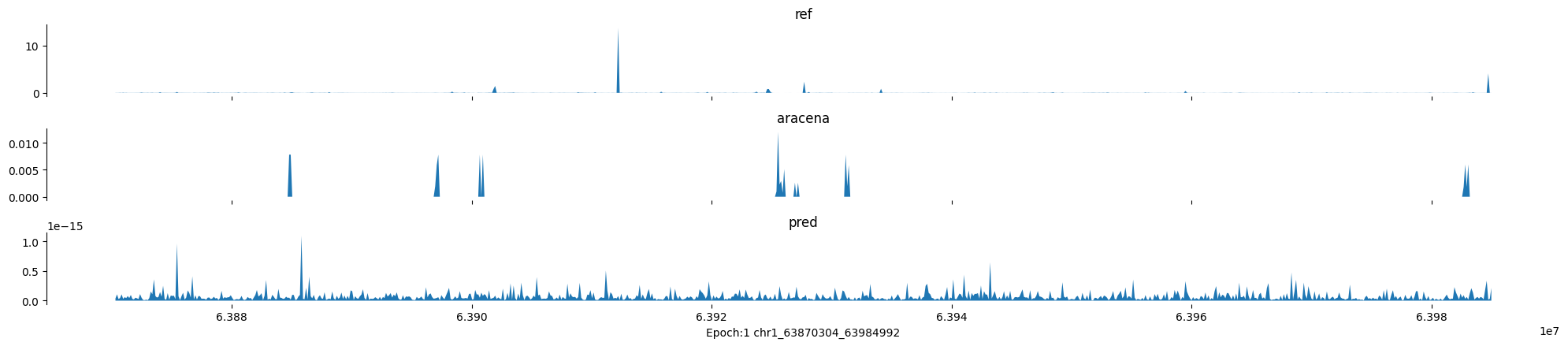
Epoch: 1
0
chr1:63870304-63984992:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
Epoch: 2
0
chr1:63870304-63984992:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
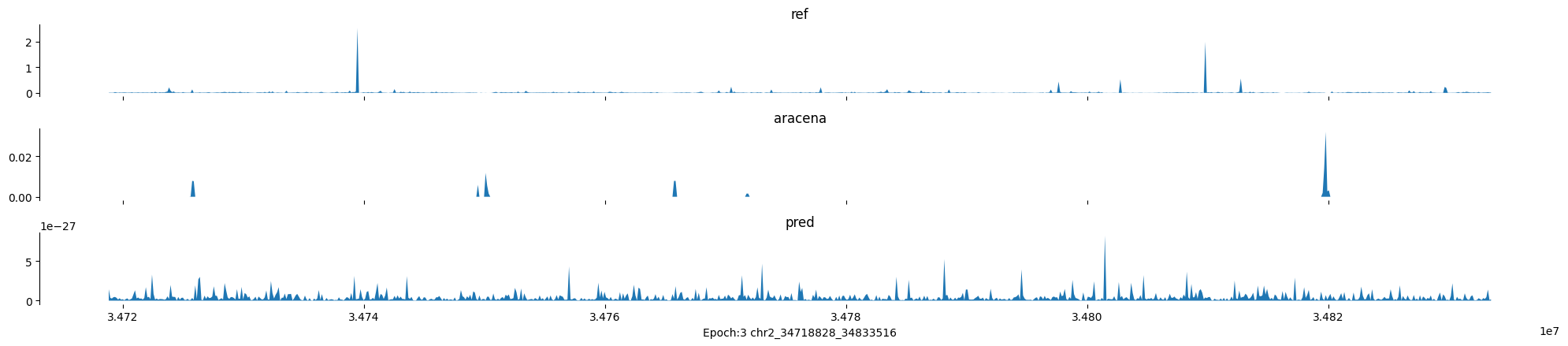
Epoch: 3
0
chr2:34718828-34833516:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
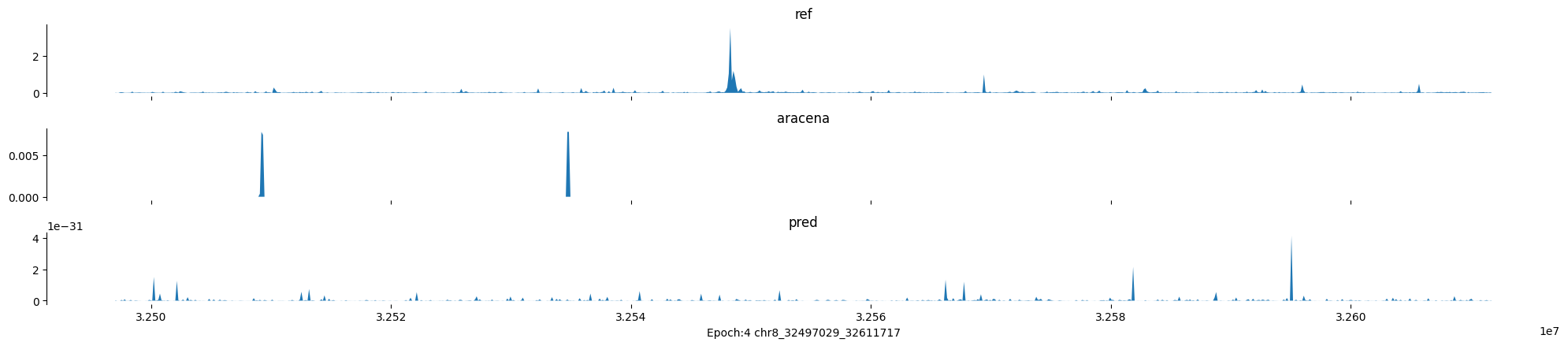
Epoch: 4
0
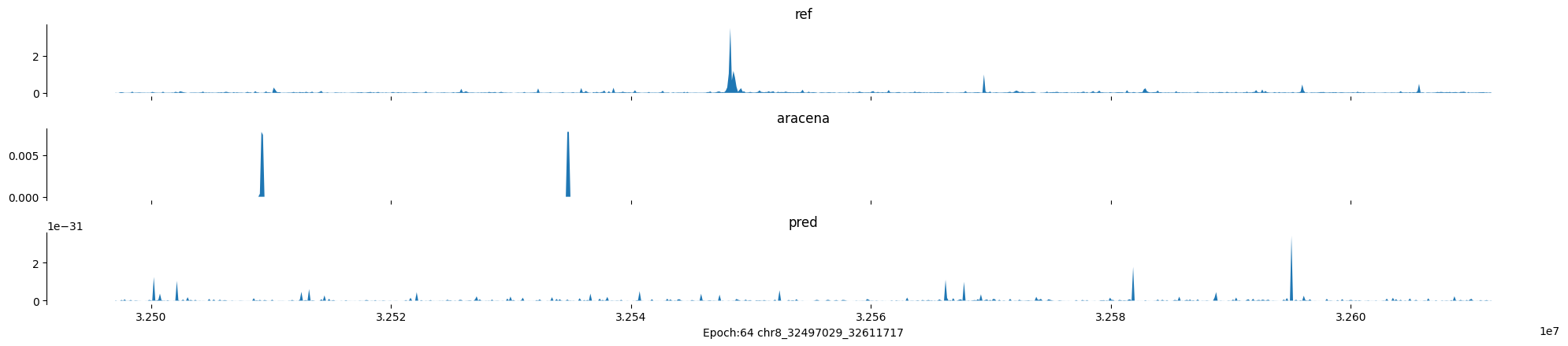
chr8:32497029-32611717:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
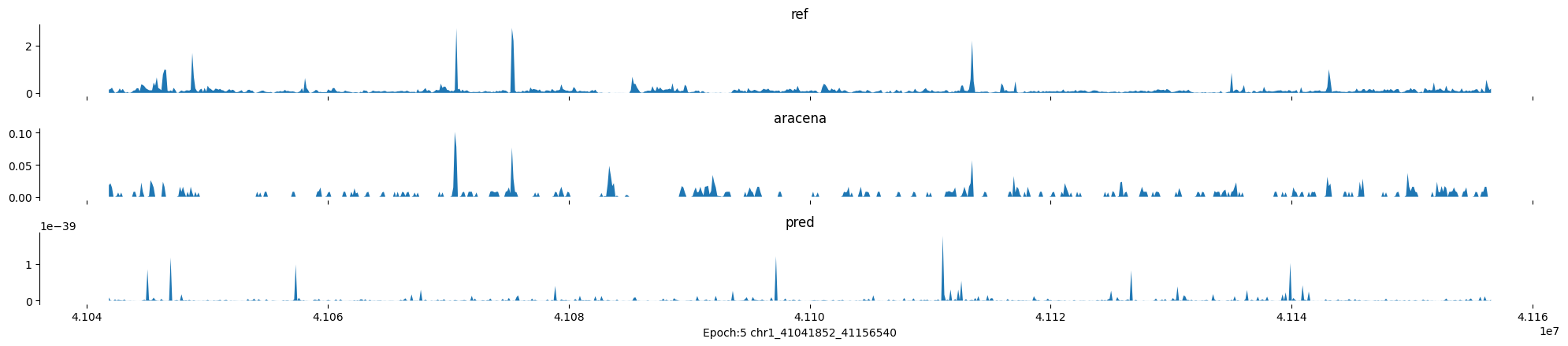
Epoch: 5
0
chr1:41041852-41156540:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
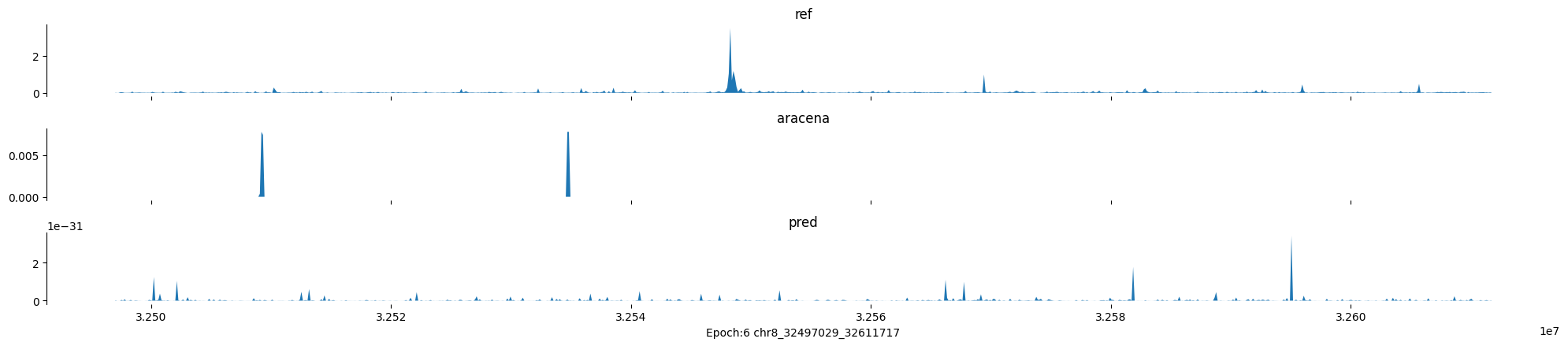
Epoch: 6
0
chr8:32497029-32611717:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
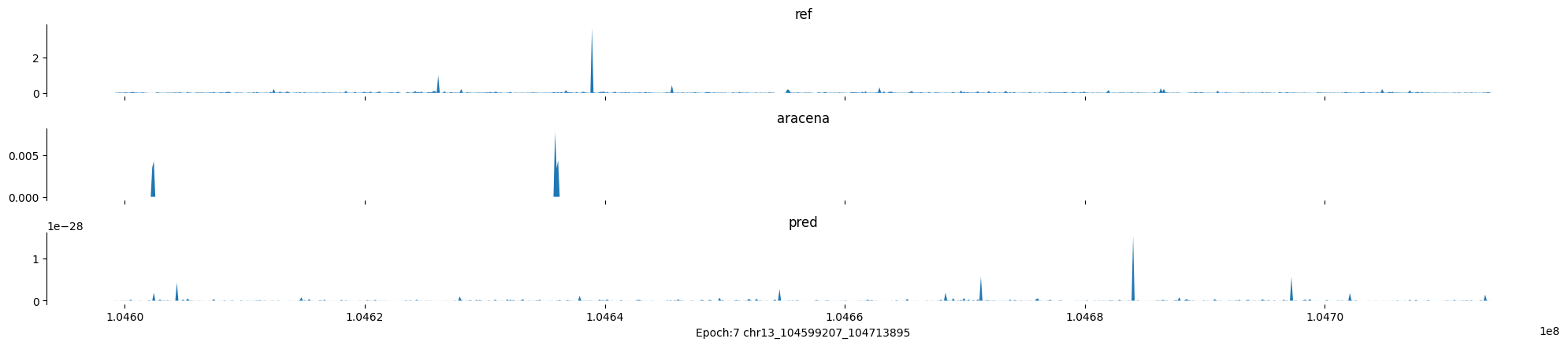
Epoch: 7
0
chr13:104599207-104713895:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
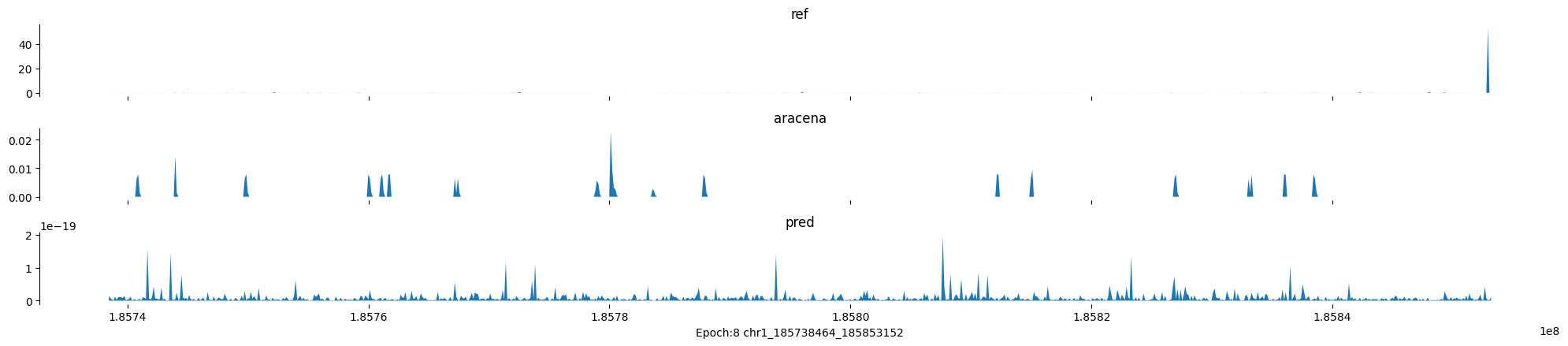
Epoch: 8
0
chr1:185738464-185853152:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
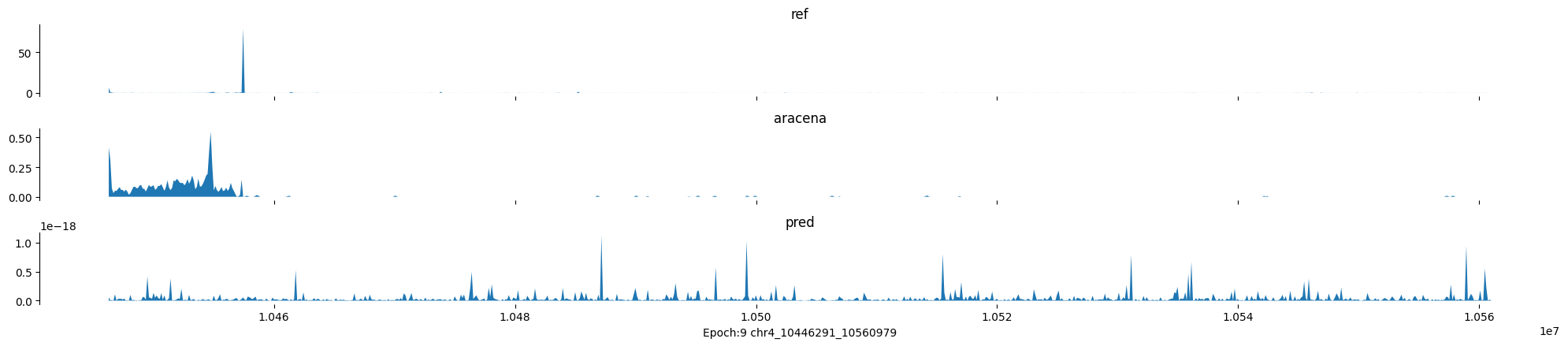
Epoch: 9
0
chr4:10446291-10560979:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
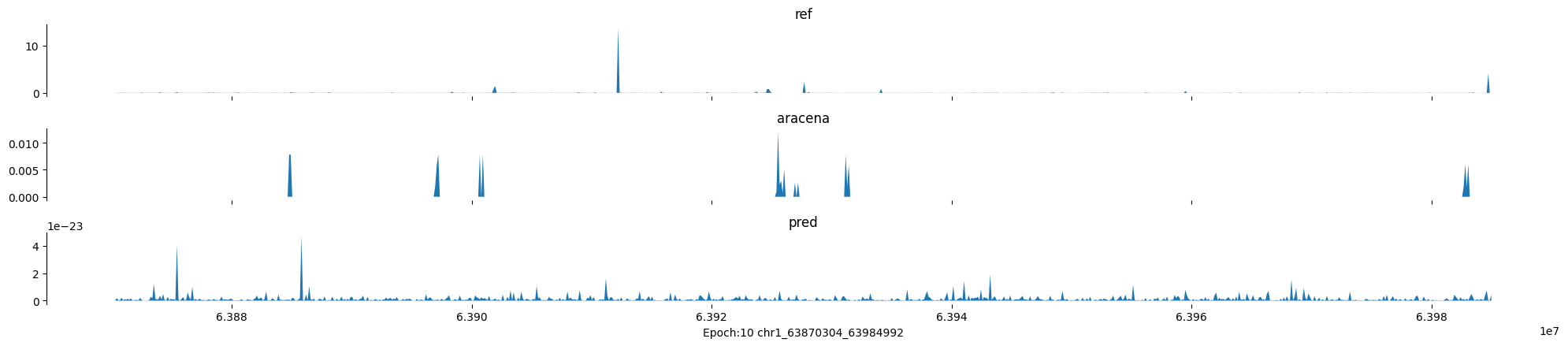
Epoch: 10
0
chr1:63870304-63984992:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
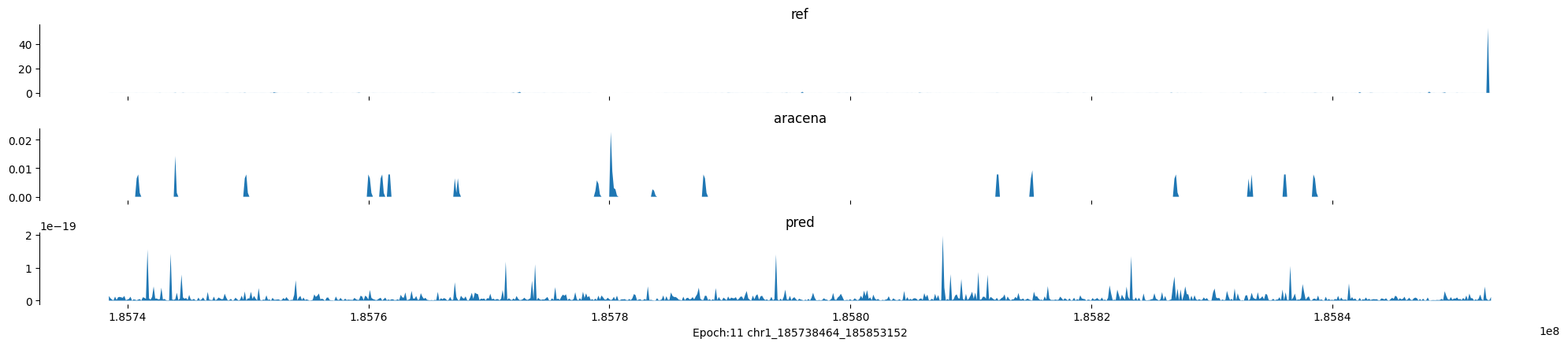
Epoch: 11
0
chr1:185738464-185853152:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
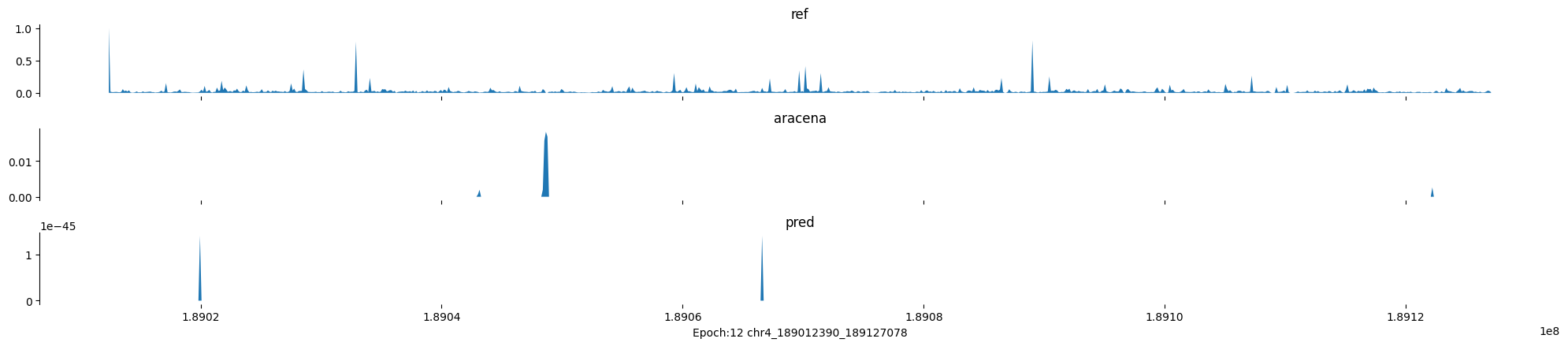
Epoch: 12
0
chr4:189012390-189127078:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
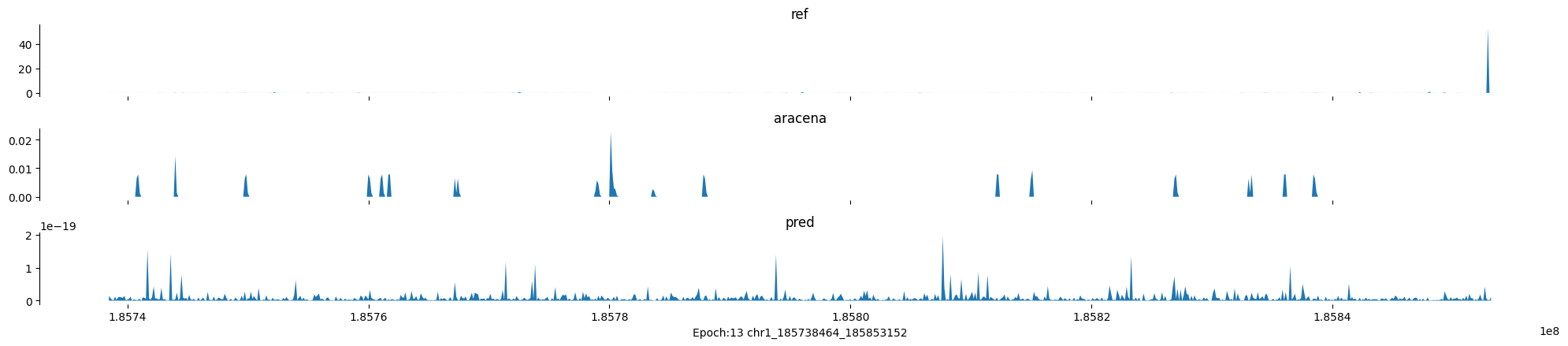
Epoch: 13
0
chr1:185738464-185853152:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
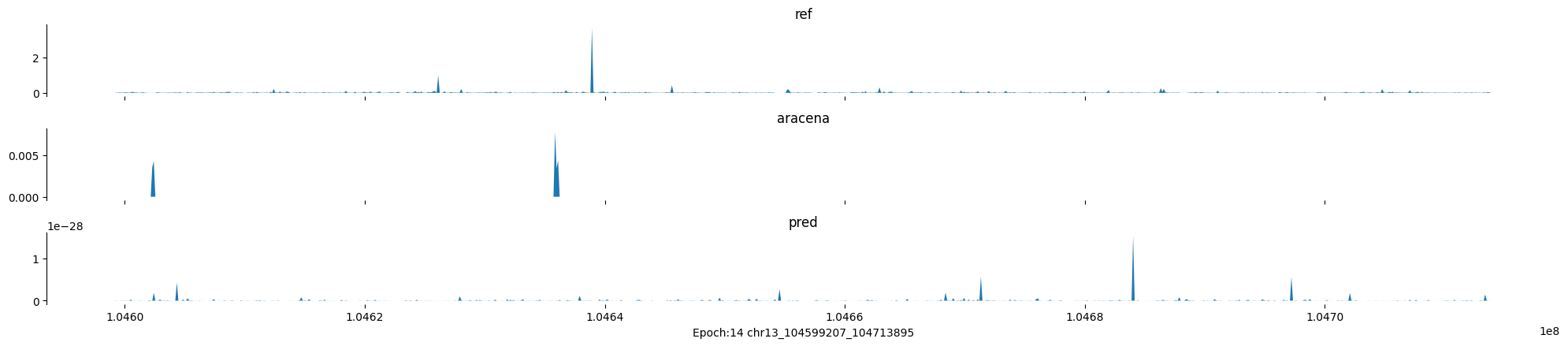
Epoch: 14
0
chr13:104599207-104713895:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
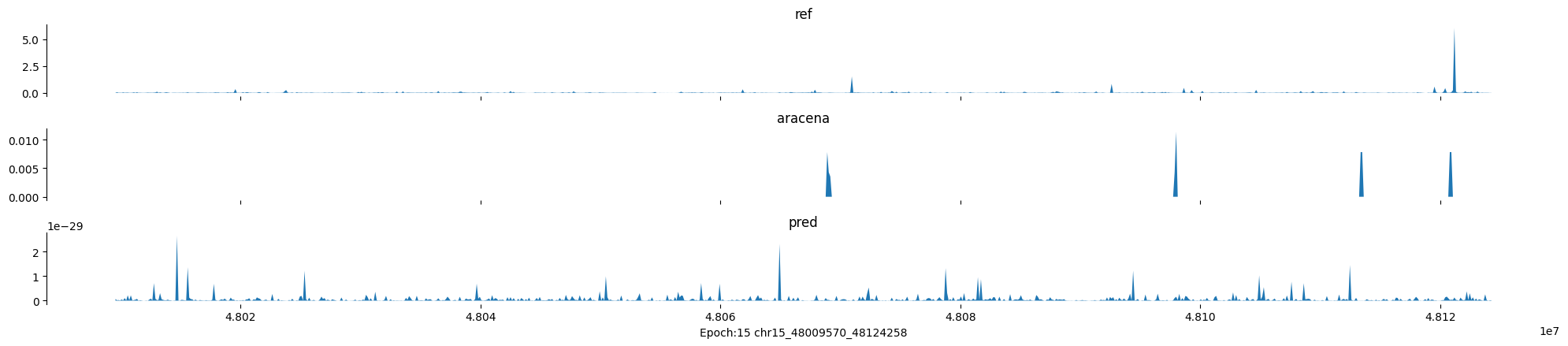
Epoch: 15
0
chr15:48009570-48124258:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
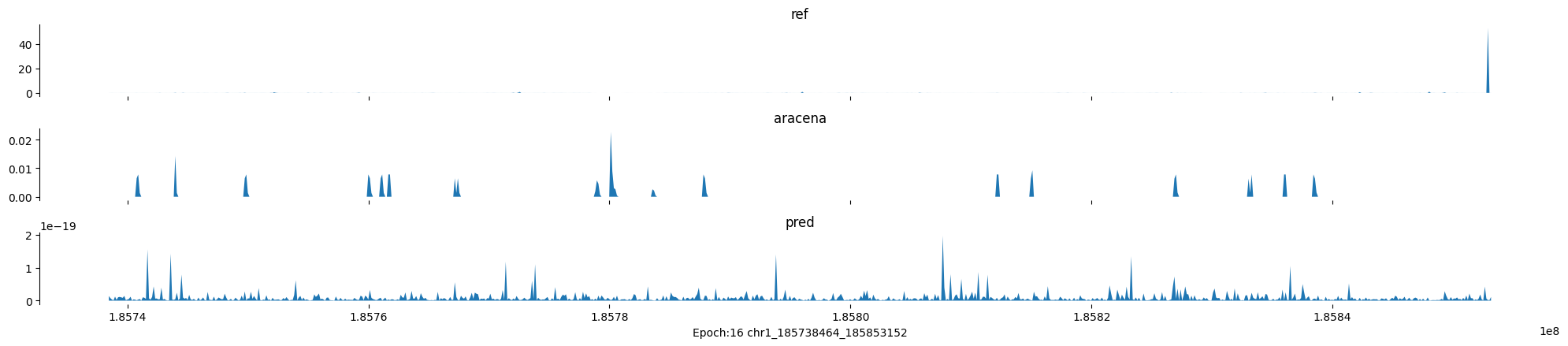
Epoch: 16
0
chr1:185738464-185853152:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
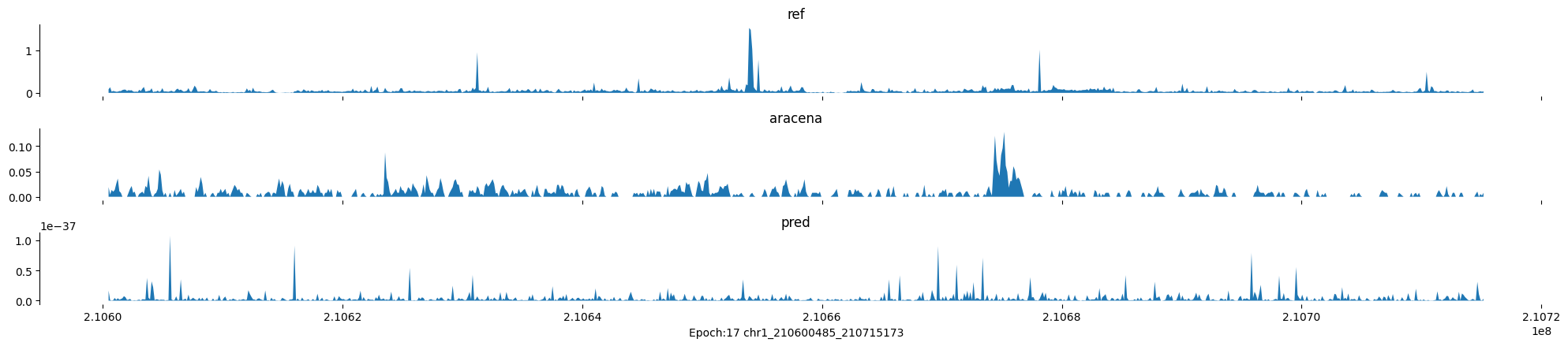
Epoch: 17
0
chr1:210600485-210715173:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
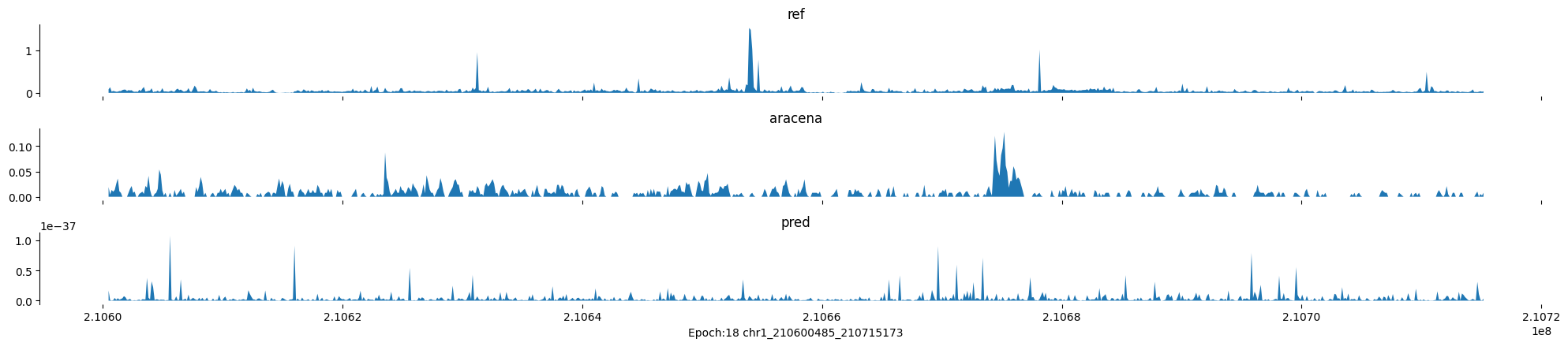
Epoch: 18
0
chr1:210600485-210715173:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
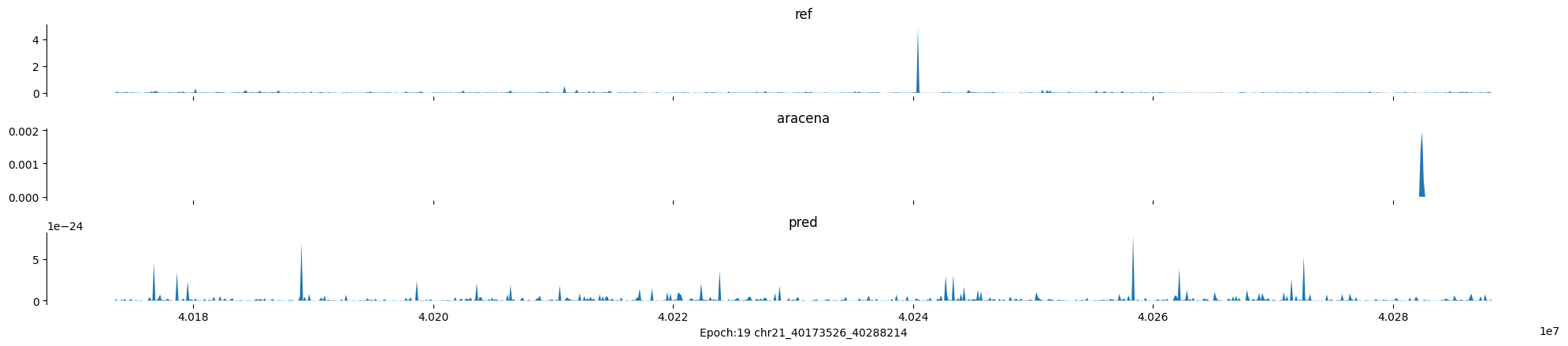
Epoch: 19
0
chr21:40173526-40288214:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
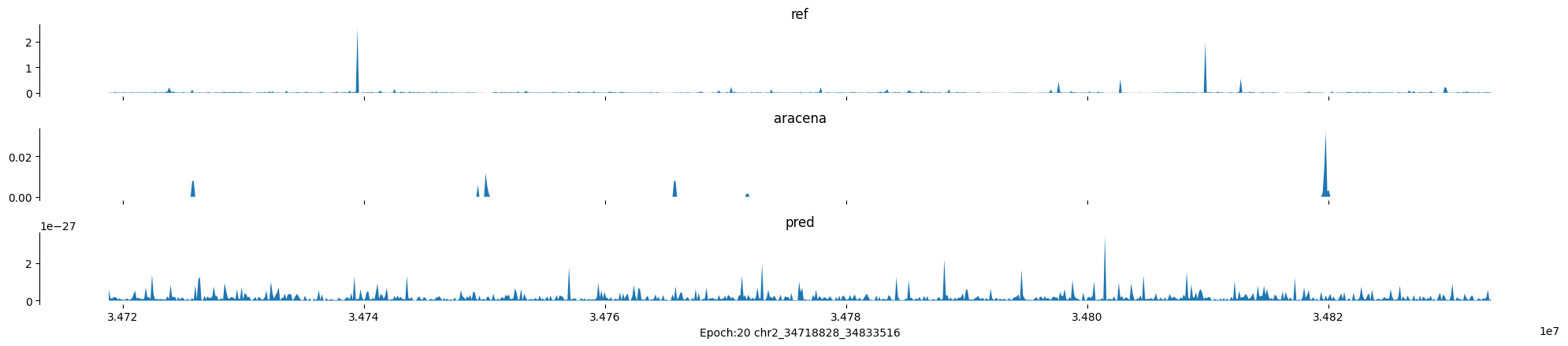
Epoch: 20
0
chr2:34718828-34833516:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
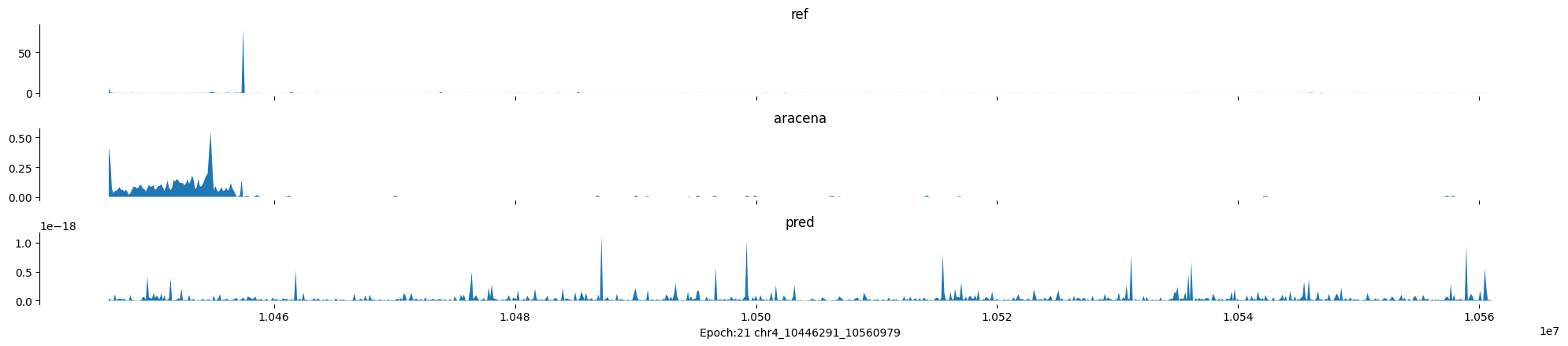
Epoch: 21
0
chr4:10446291-10560979:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
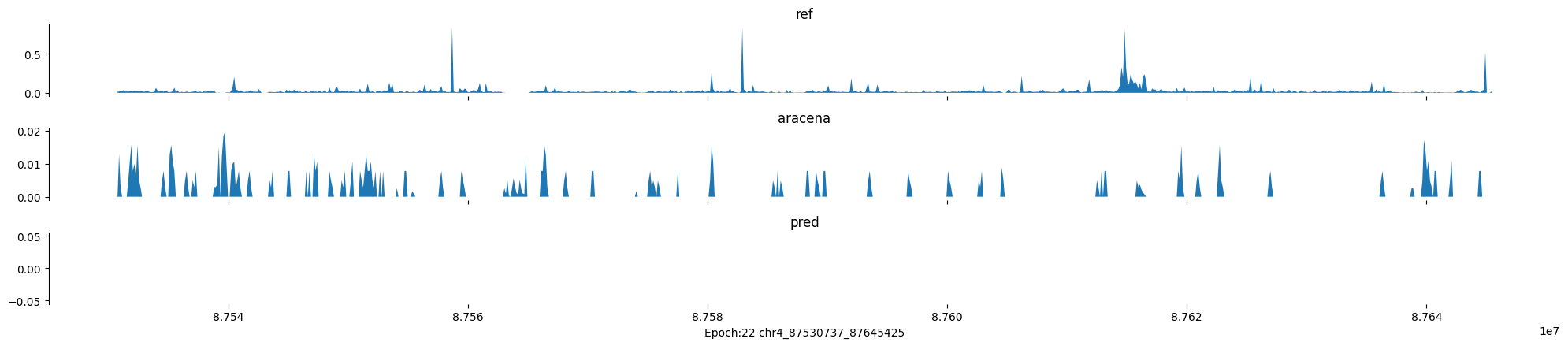
Epoch: 22
0
chr4:87530737-87645425:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
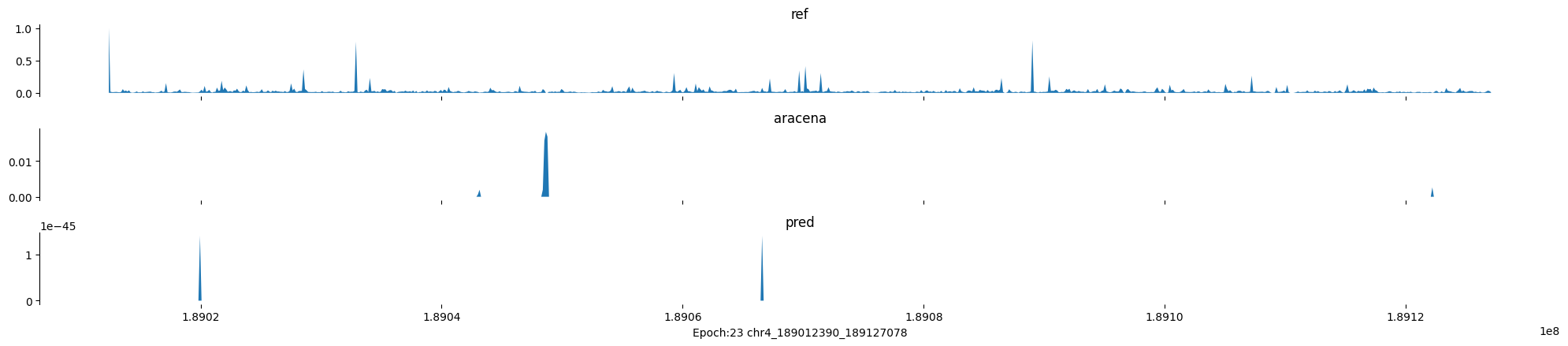
Epoch: 23
0
chr4:189012390-189127078:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
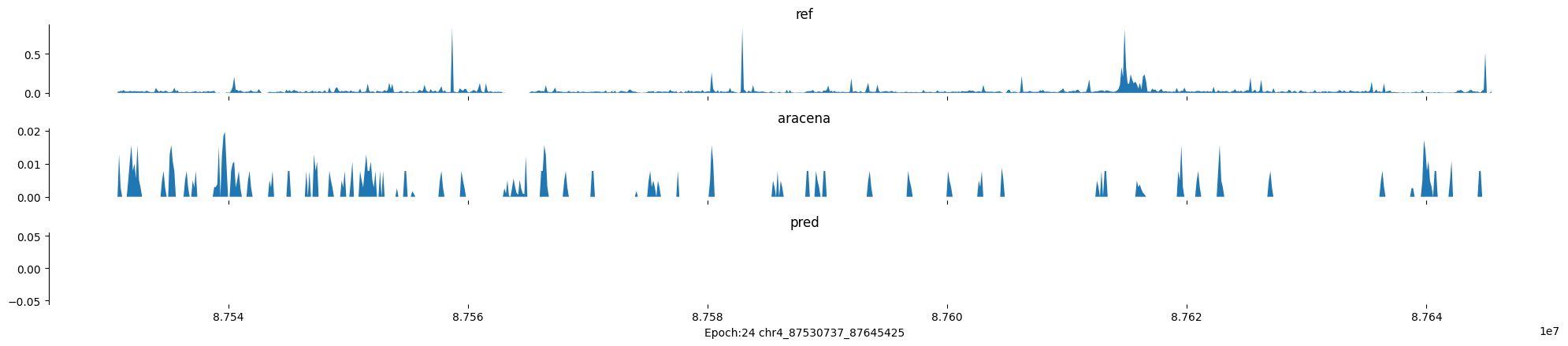
Epoch: 24
0
chr4:87530737-87645425:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
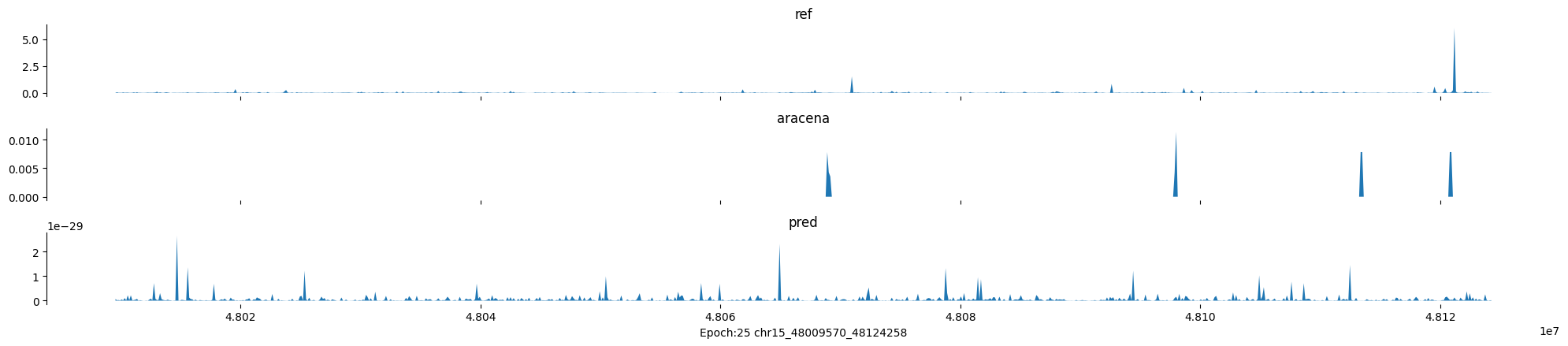
Epoch: 25
0
chr15:48009570-48124258:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
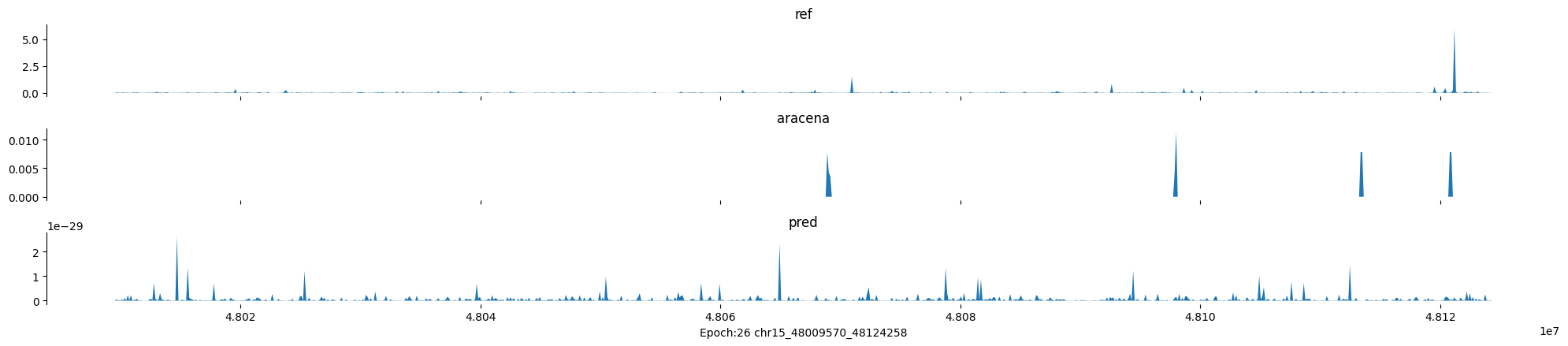
Epoch: 26
0
chr15:48009570-48124258:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
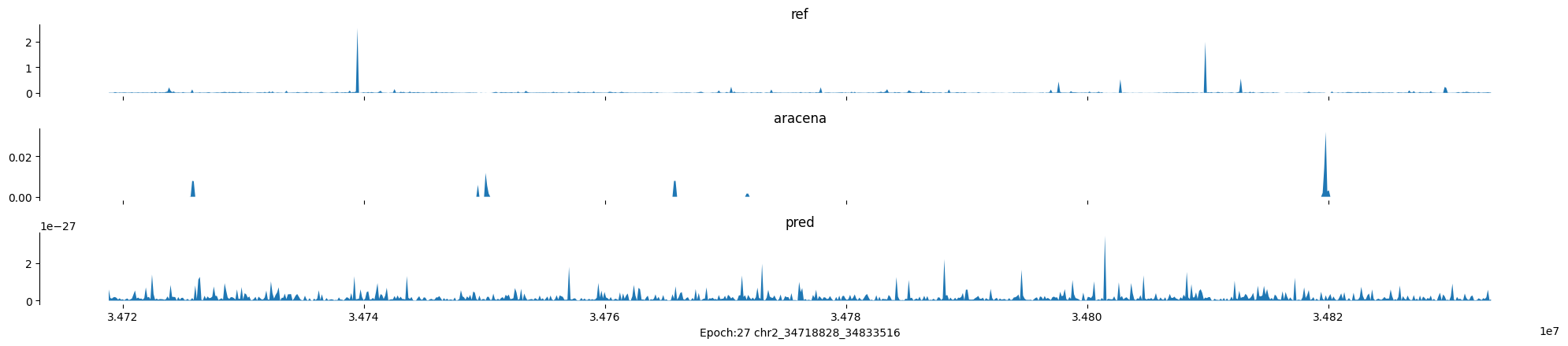
Epoch: 27
0
chr2:34718828-34833516:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
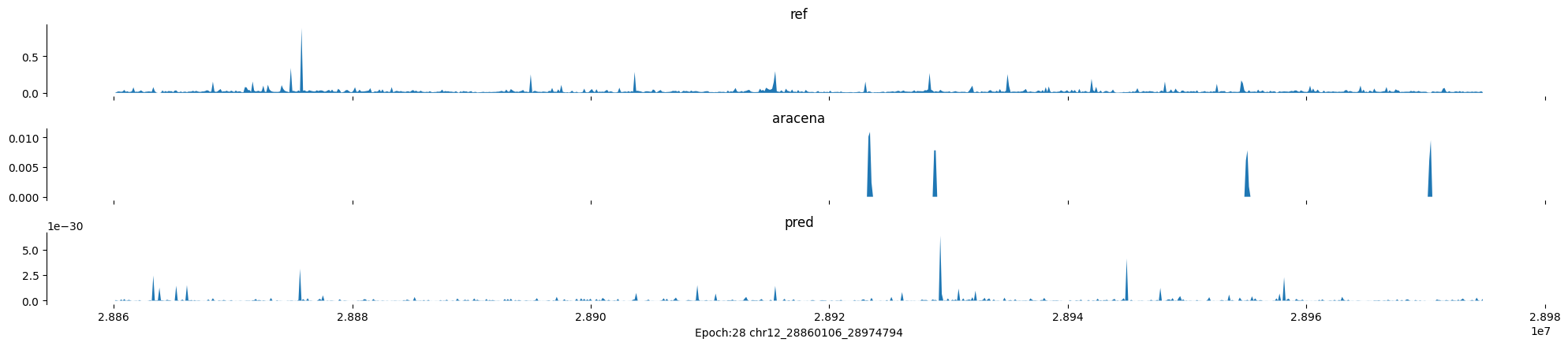
Epoch: 28
0
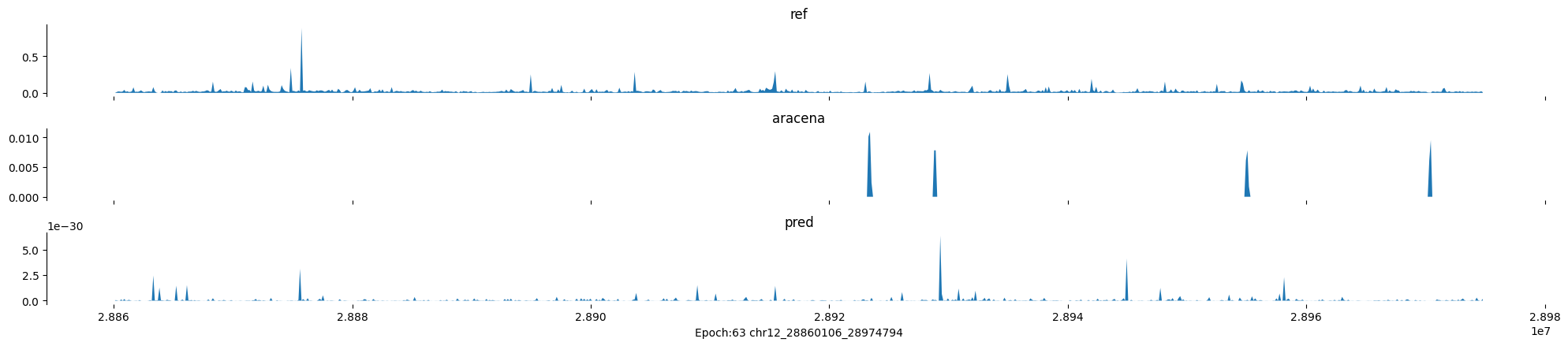
chr12:28860106-28974794:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
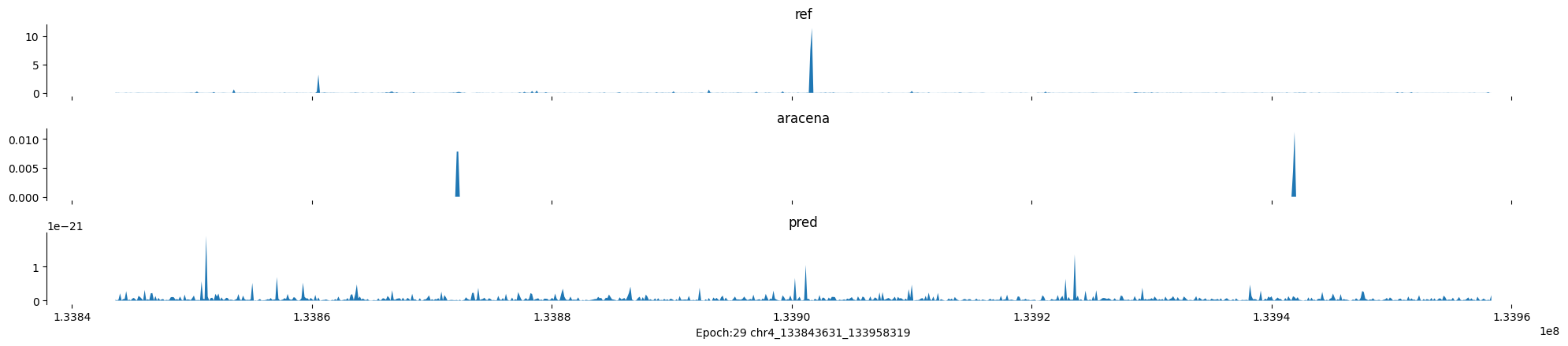
Epoch: 29
0
chr4:133843631-133958319:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
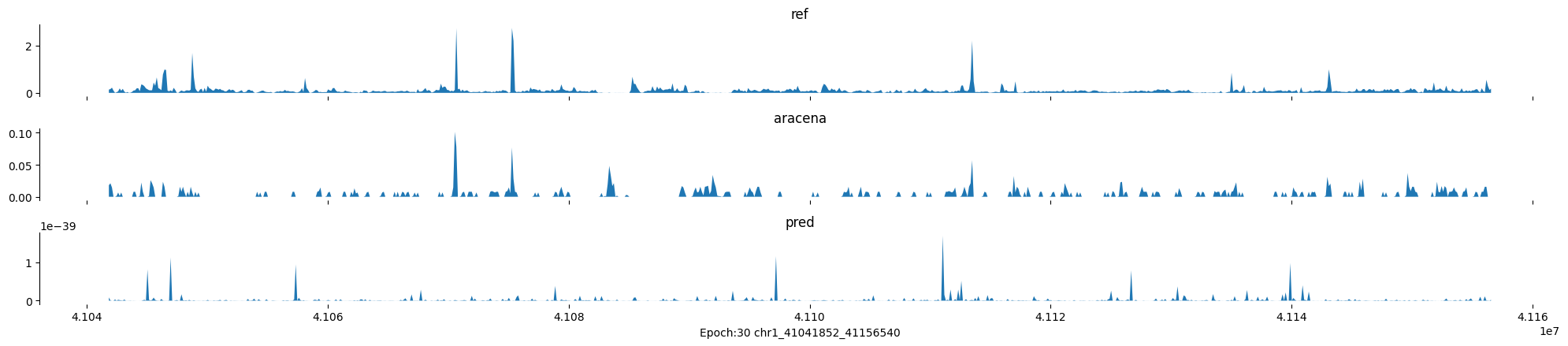
Epoch: 30
0
chr1:41041852-41156540:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
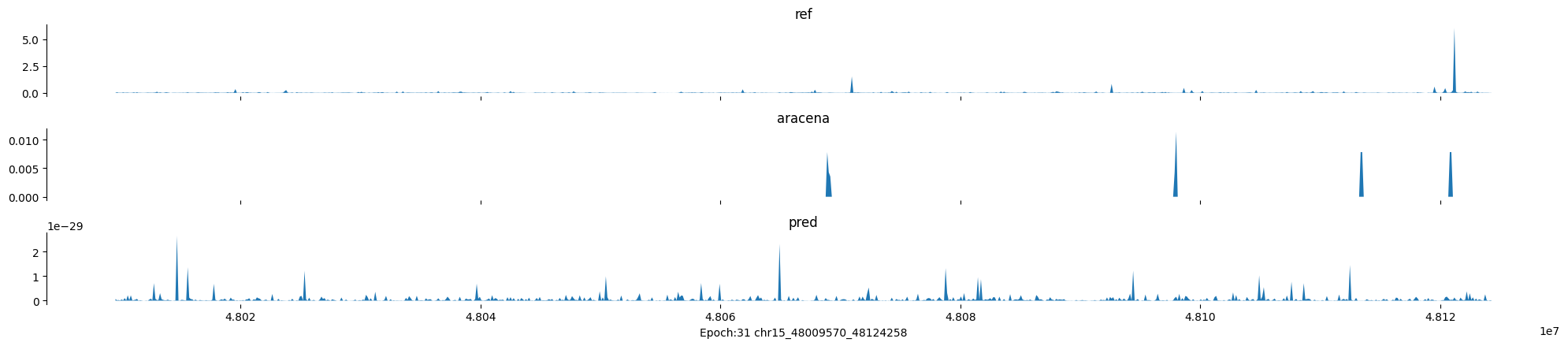
Epoch: 31
0
chr15:48009570-48124258:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
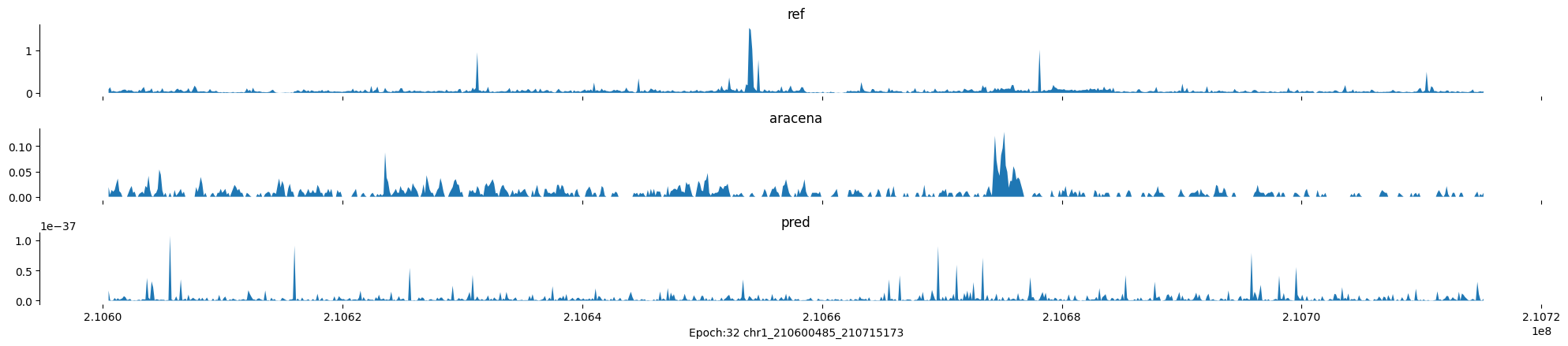
Epoch: 32
0
chr1:210600485-210715173:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
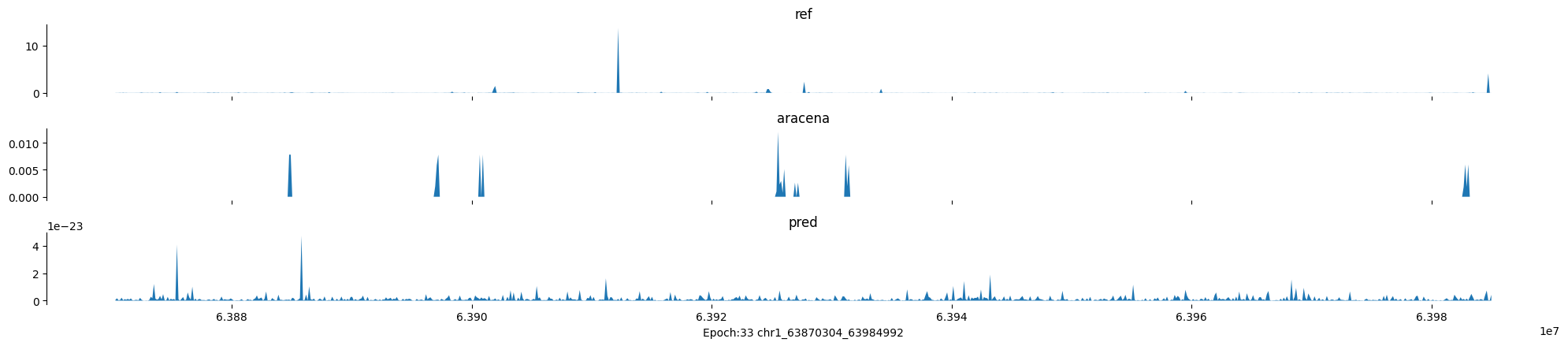
Epoch: 33
0
chr1:63870304-63984992:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
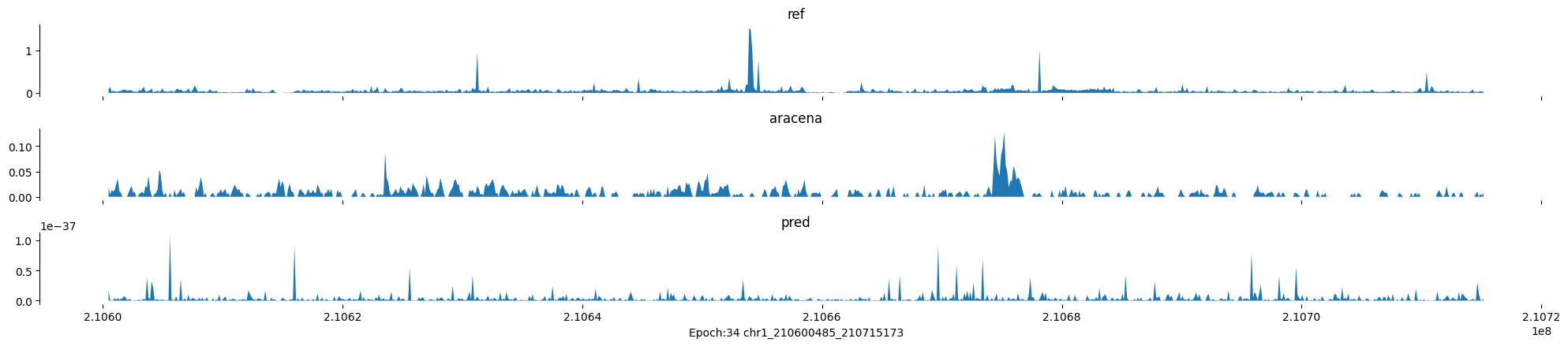
Epoch: 34
0
chr1:210600485-210715173:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
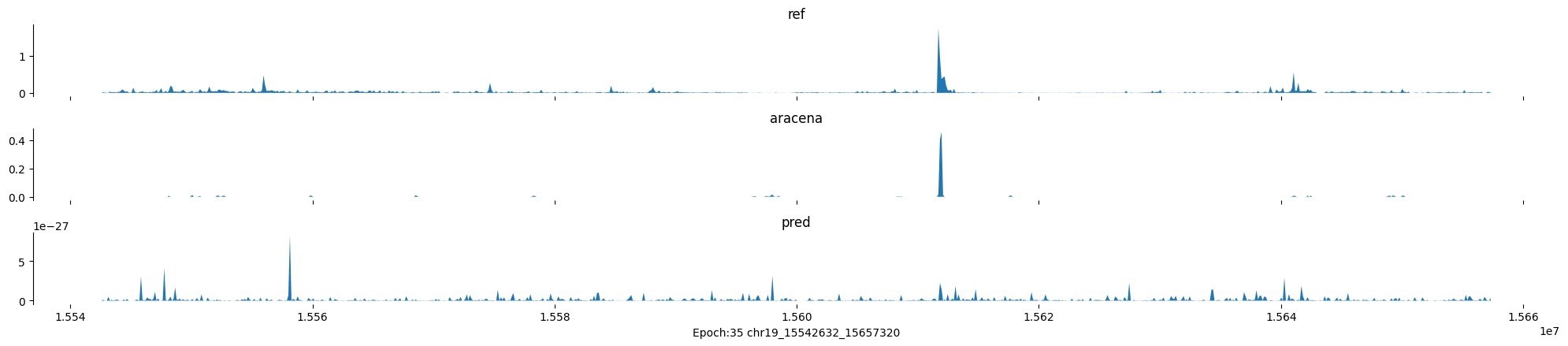
Epoch: 35
0
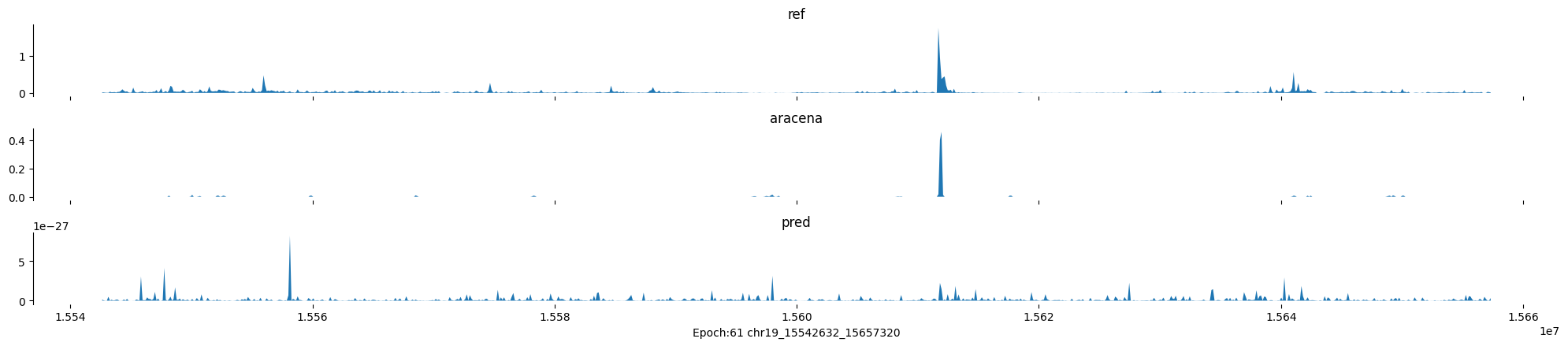
chr19:15542632-15657320:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
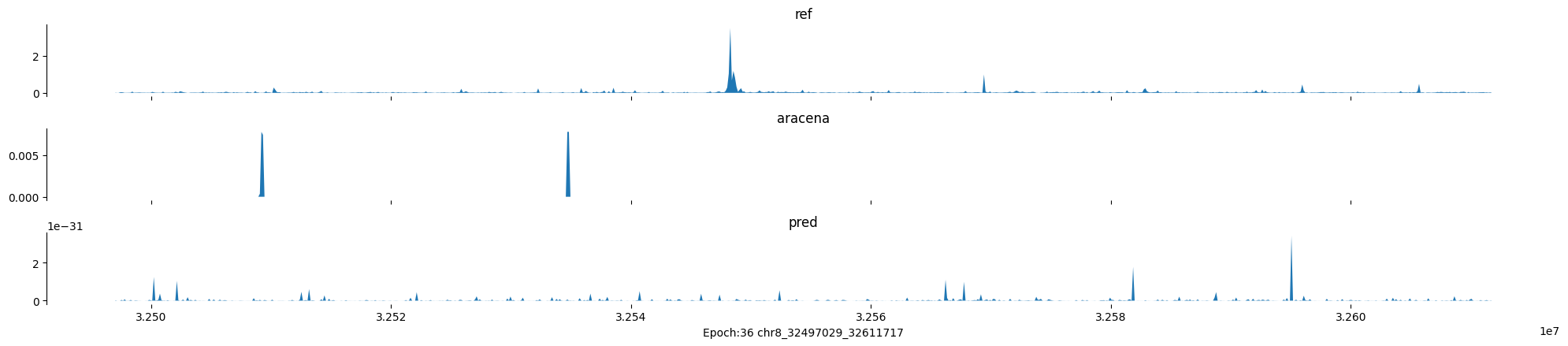
Epoch: 36
0
chr8:32497029-32611717:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
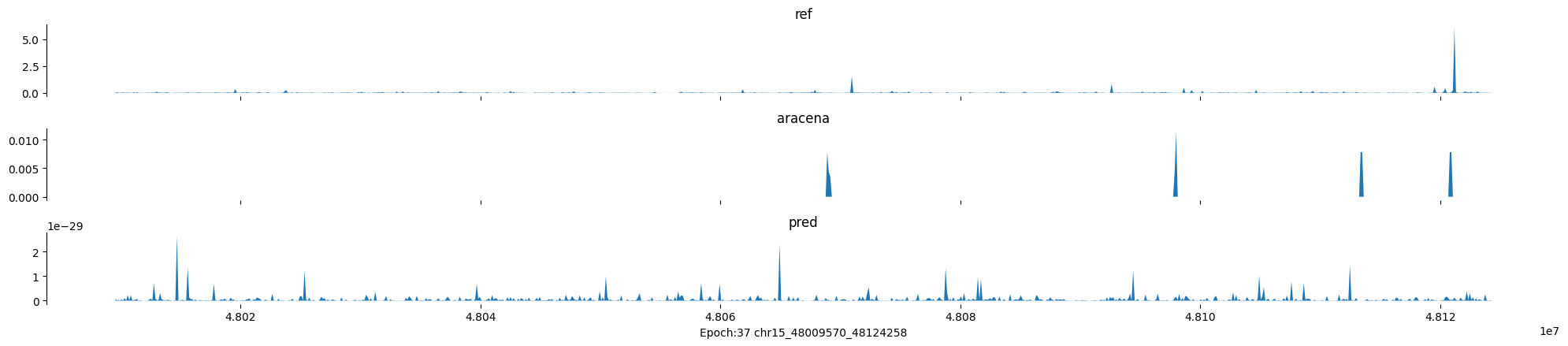
Epoch: 37
0
chr15:48009570-48124258:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
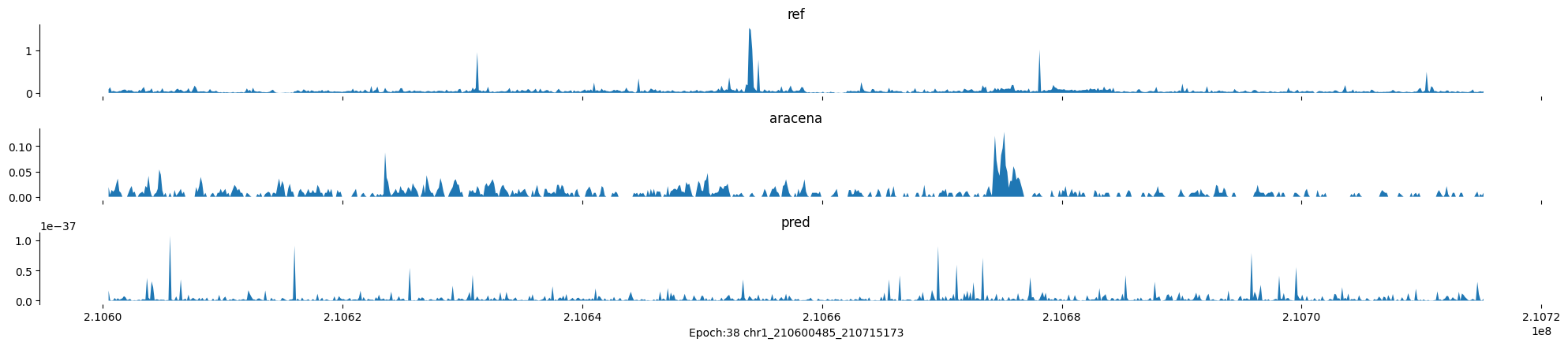
Epoch: 38
0
chr1:210600485-210715173:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
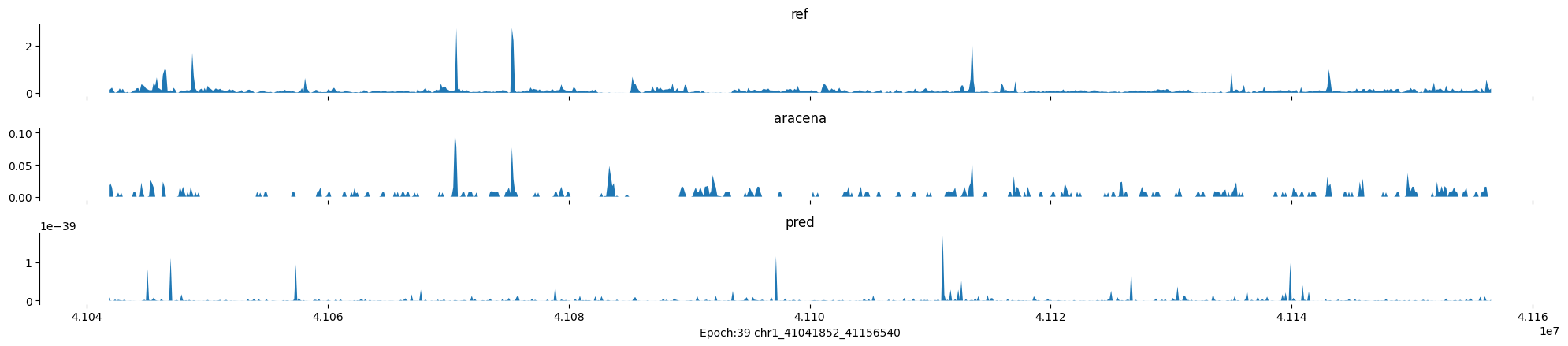
Epoch: 39
0
chr1:41041852-41156540:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
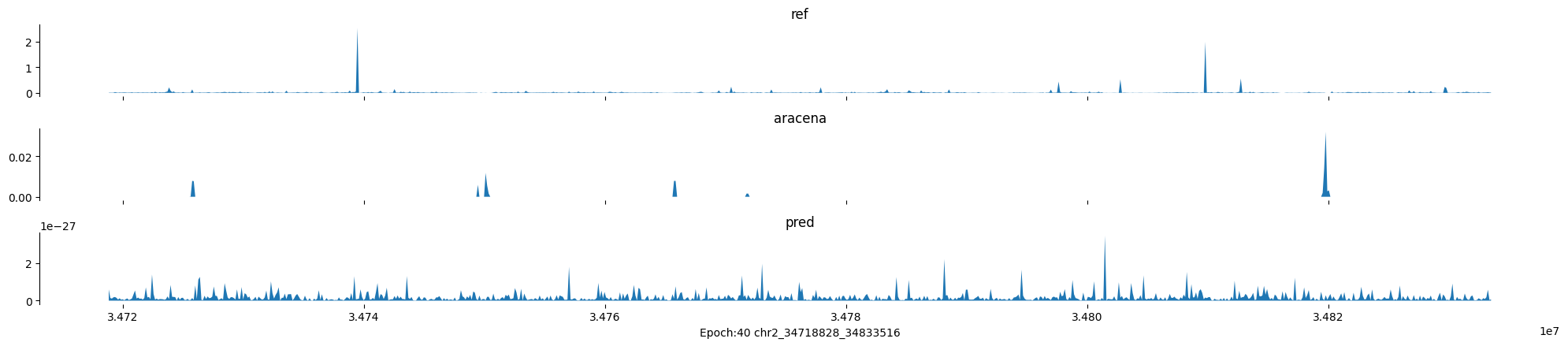
Epoch: 40
0
chr2:34718828-34833516:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
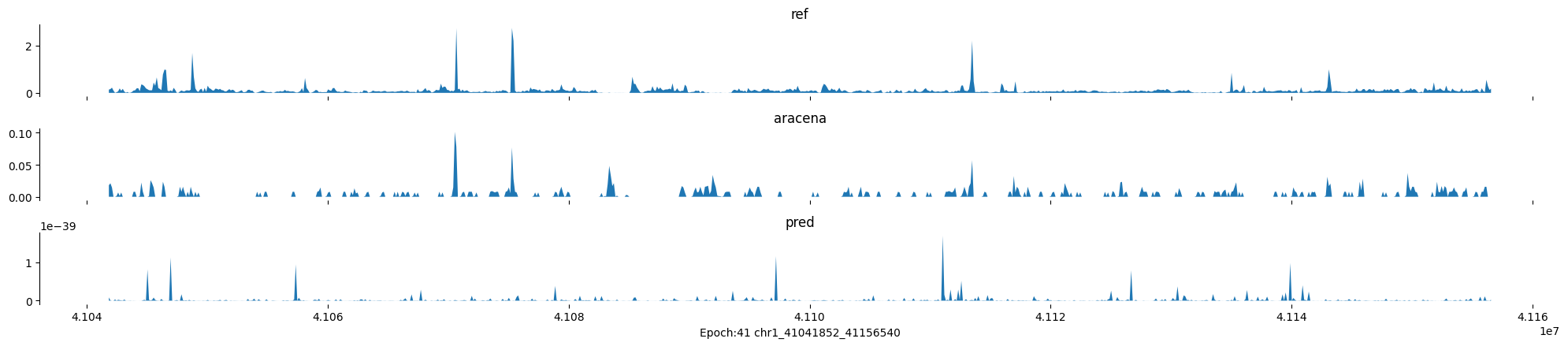
Epoch: 41
0
chr1:41041852-41156540:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
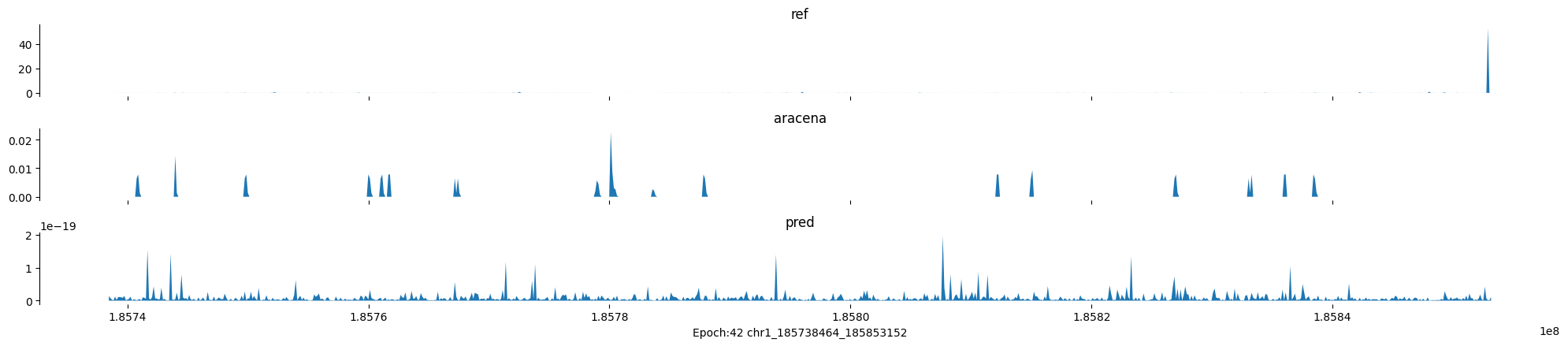
Epoch: 42
0
chr1:185738464-185853152:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
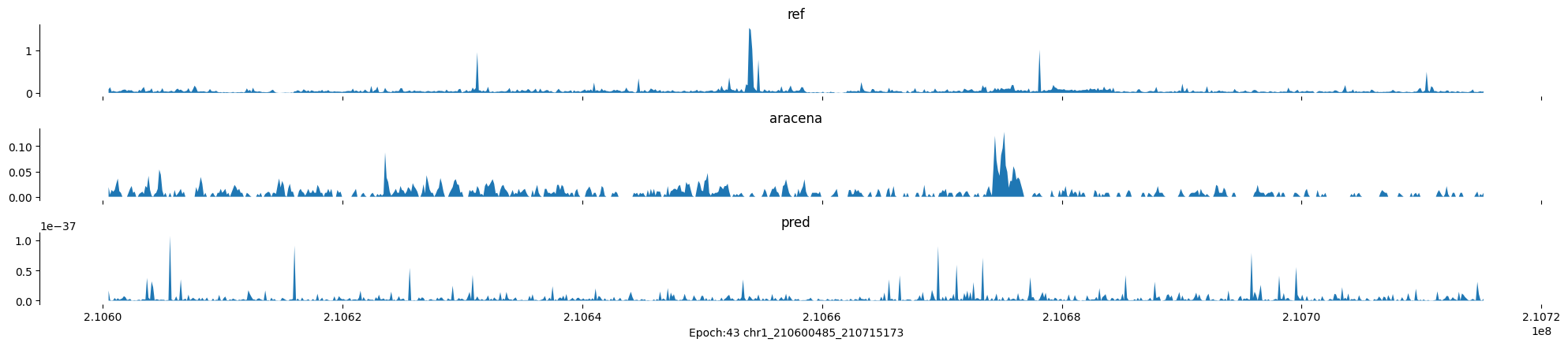
Epoch: 43
0
chr1:210600485-210715173:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
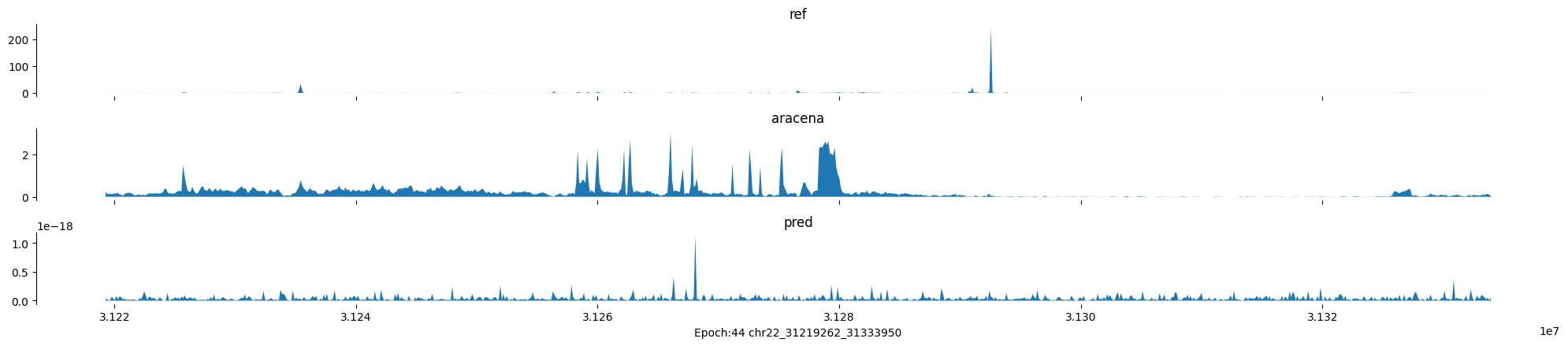
Epoch: 44
0
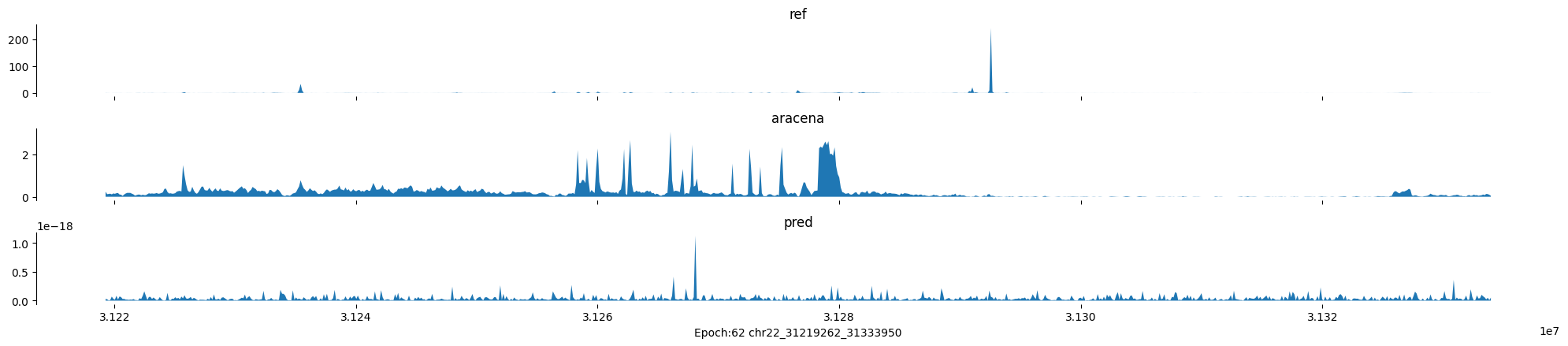
chr22:31219262-31333950:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
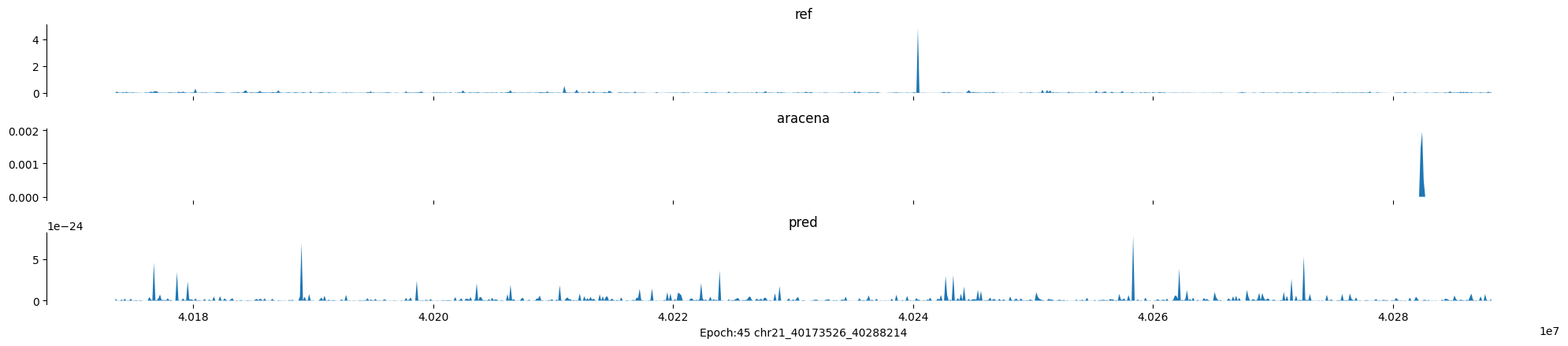
Epoch: 45
0
chr21:40173526-40288214:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
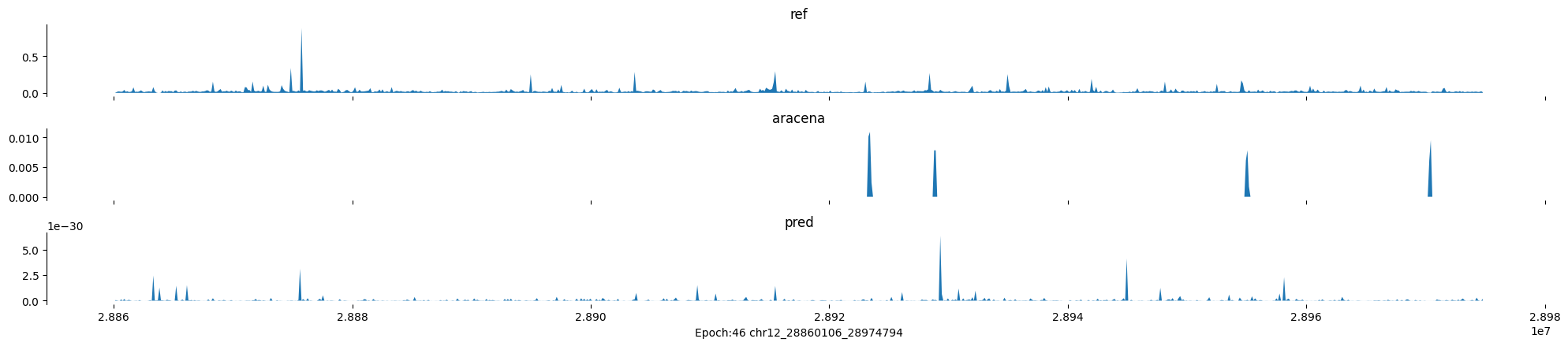
Epoch: 46
0
chr12:28860106-28974794:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
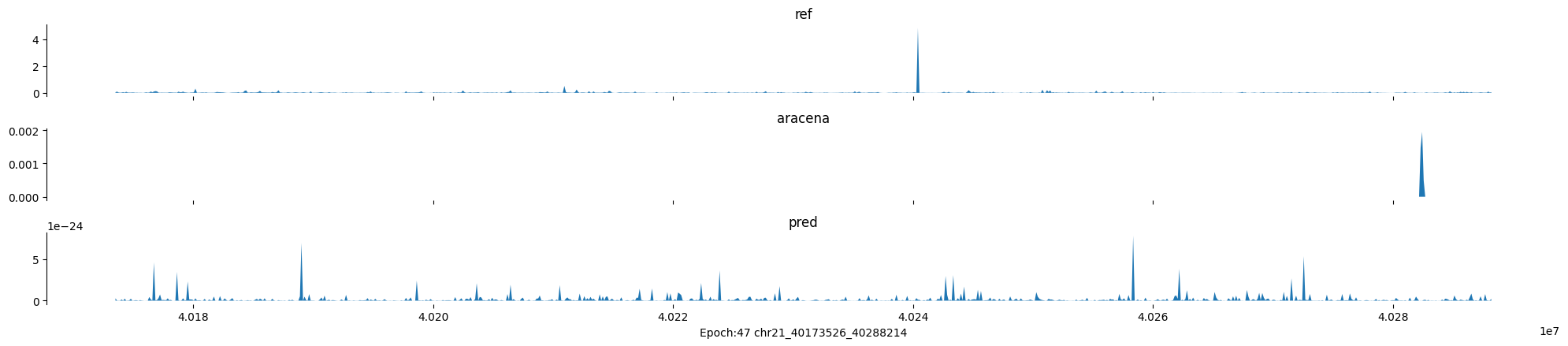
Epoch: 47
0
chr21:40173526-40288214:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
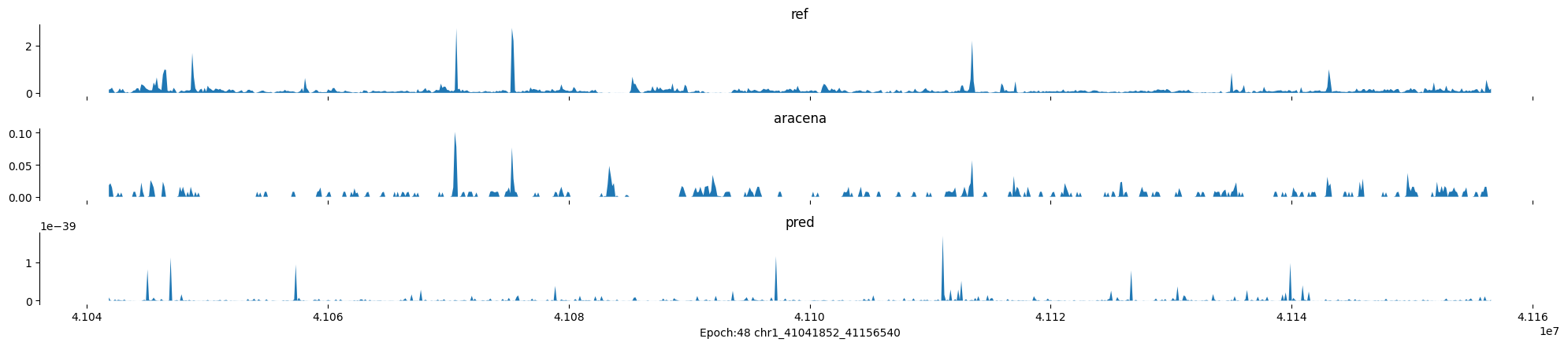
Epoch: 48
0
chr1:41041852-41156540:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
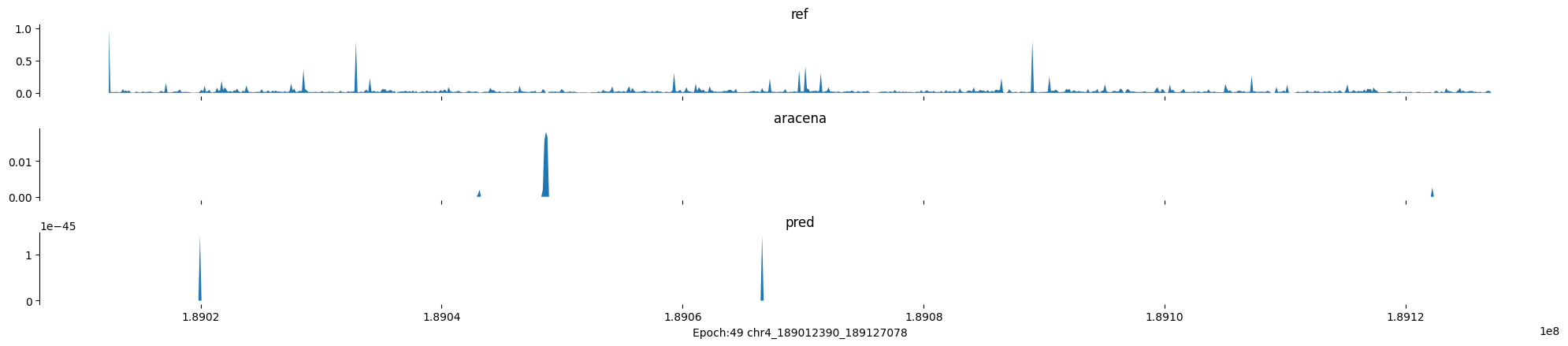
Epoch: 49
0
chr4:189012390-189127078:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
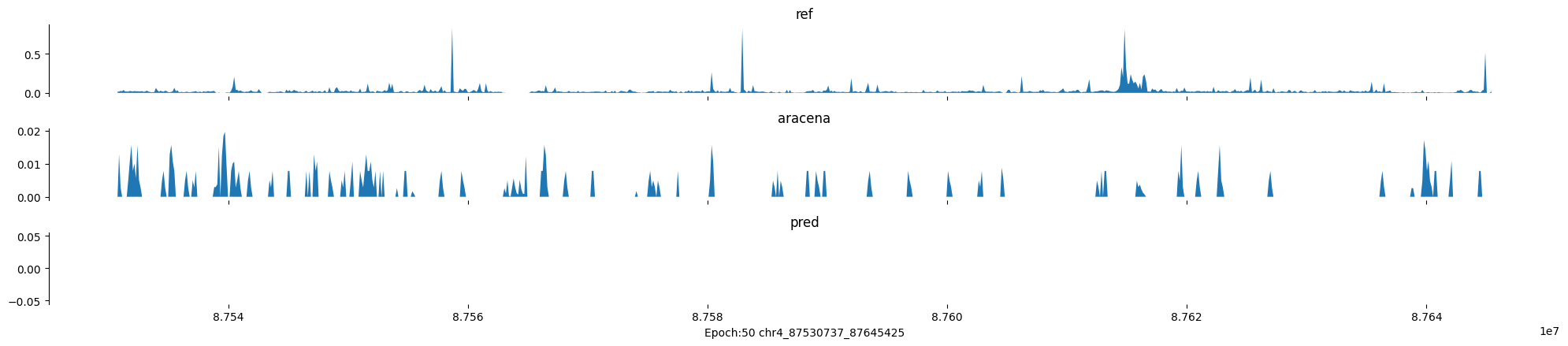
Epoch: 50
0
chr4:87530737-87645425:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
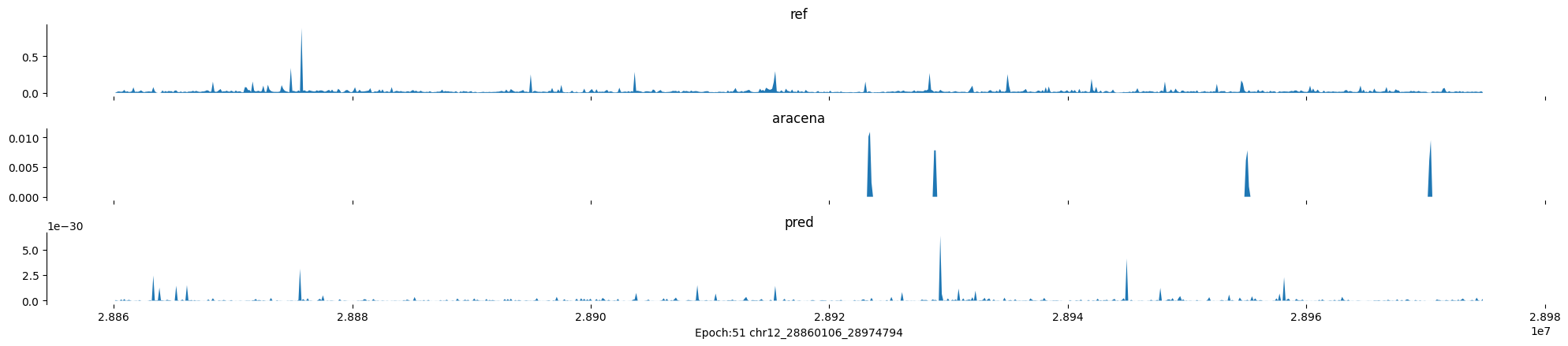
Epoch: 51
0
chr12:28860106-28974794:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
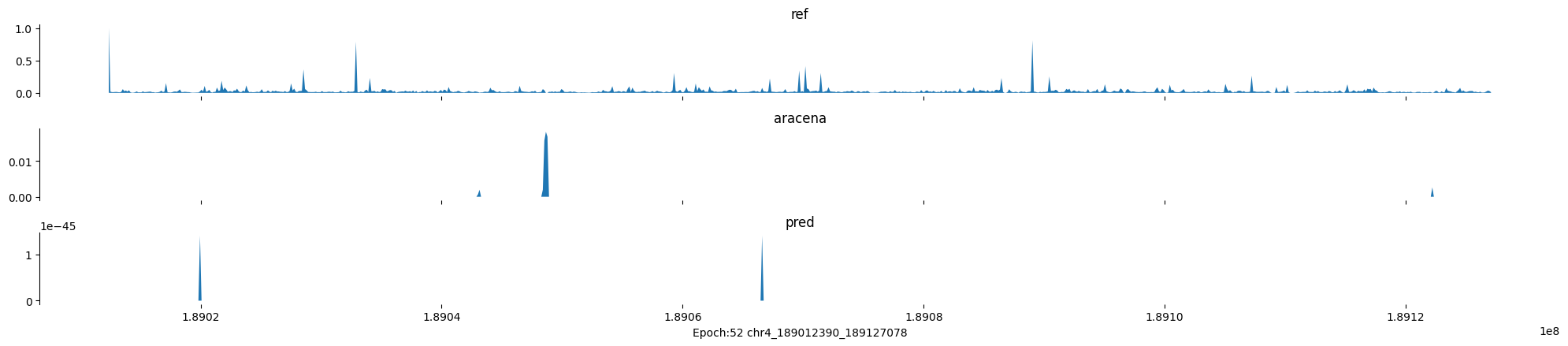
Epoch: 52
0
chr4:189012390-189127078:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
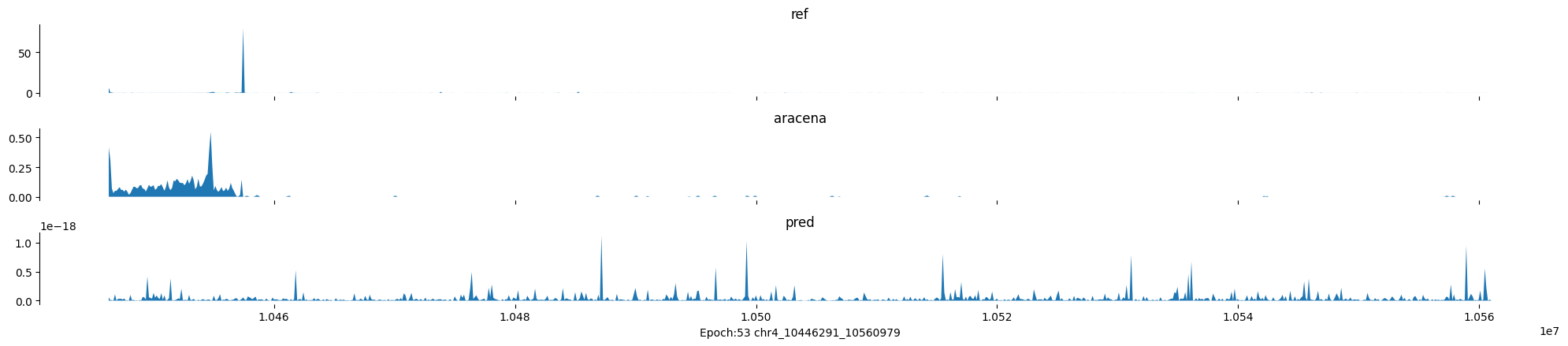
Epoch: 53
0
chr4:10446291-10560979:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
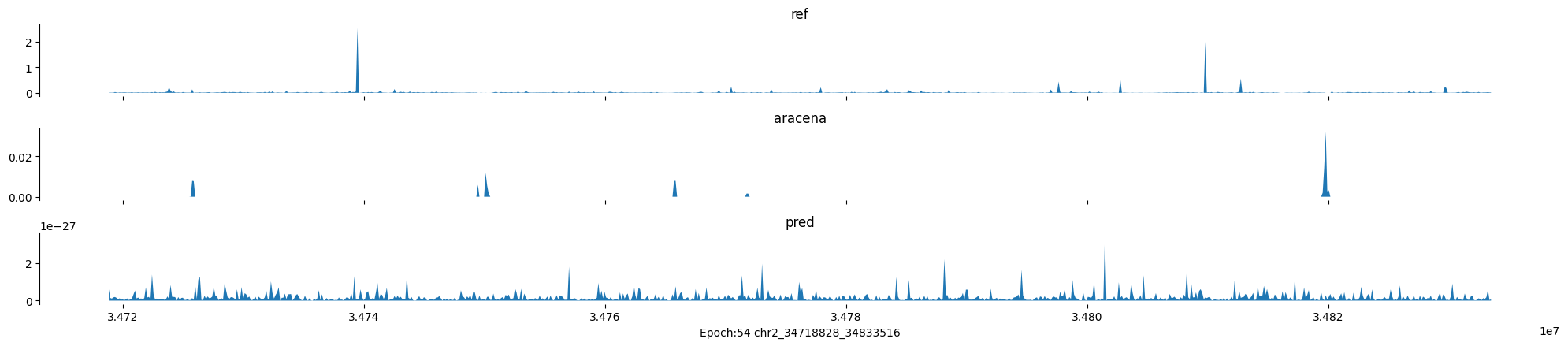
Epoch: 54
0
chr2:34718828-34833516:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
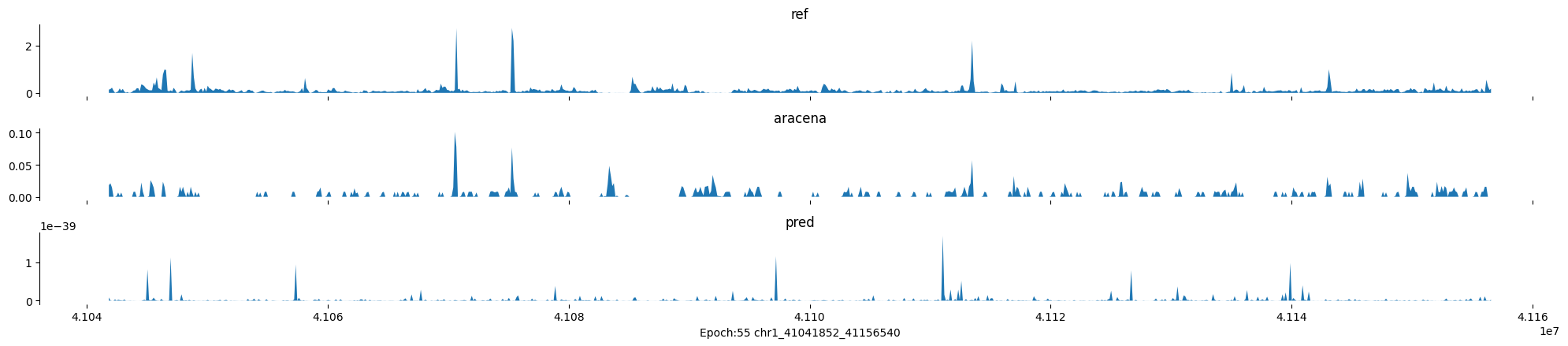
Epoch: 55
0
chr1:41041852-41156540:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
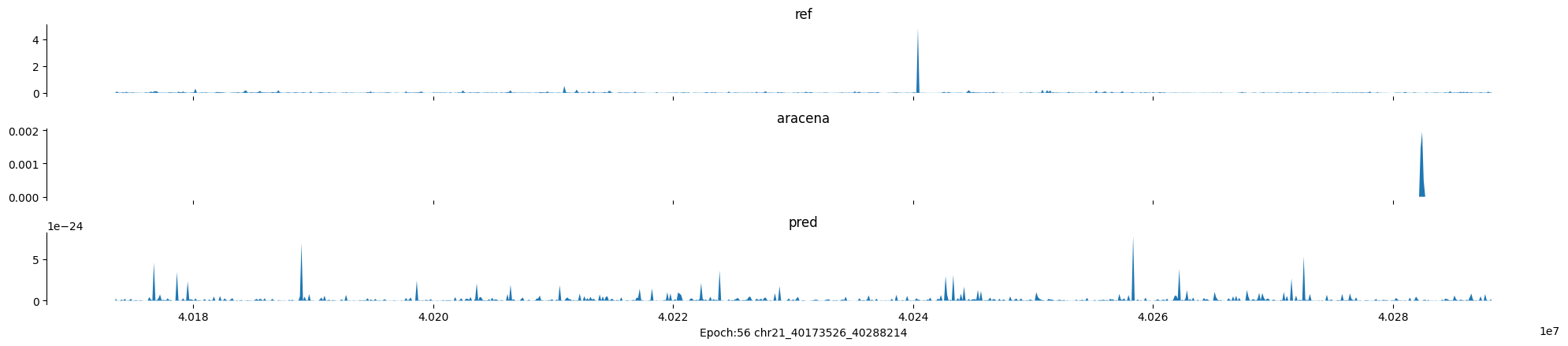
Epoch: 56
0
chr21:40173526-40288214:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
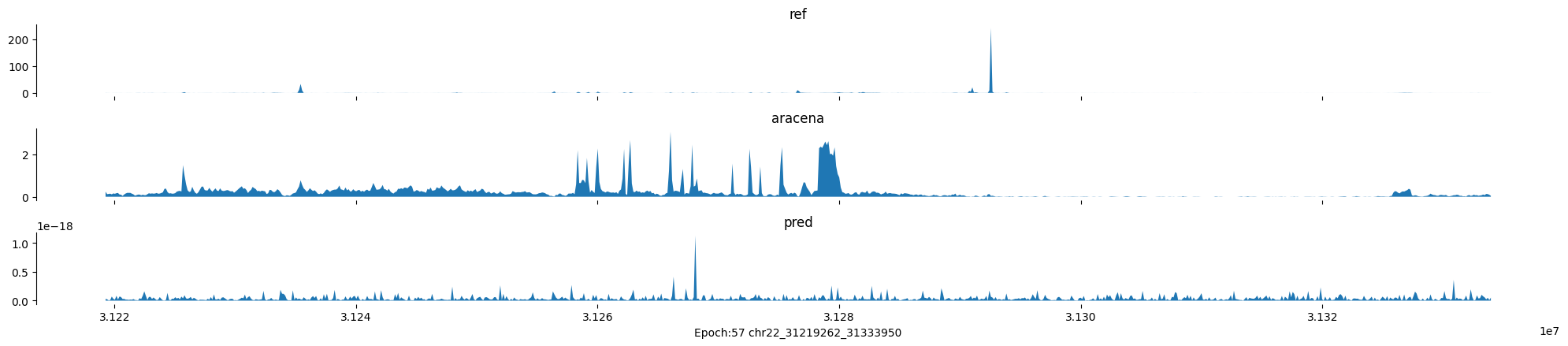
Epoch: 57
0
chr22:31219262-31333950:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
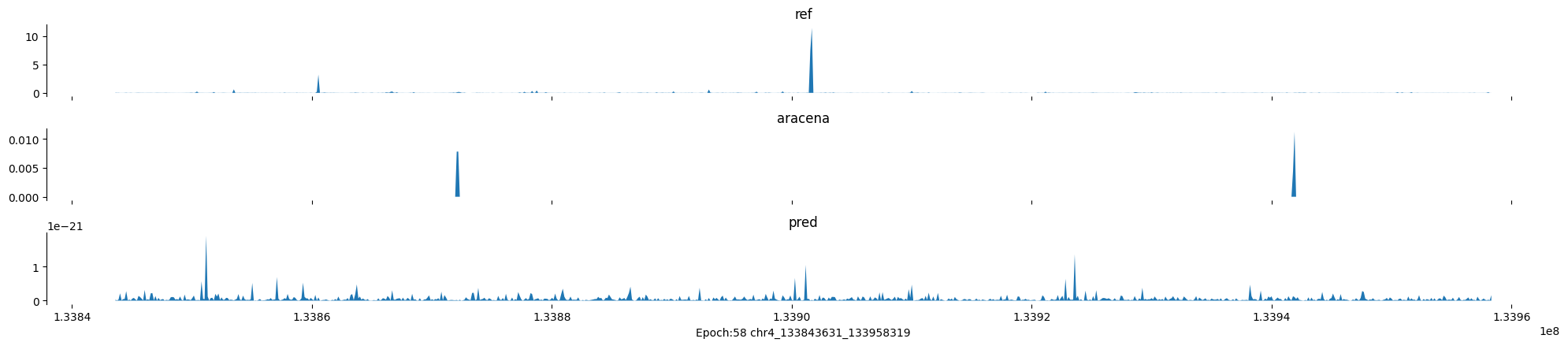
Epoch: 58
0
chr4:133843631-133958319:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
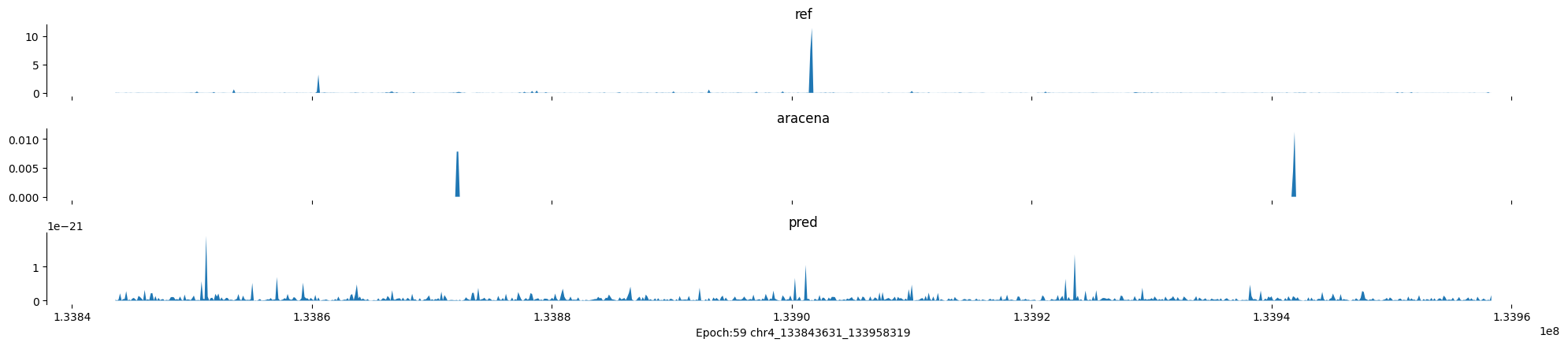
Epoch: 59
0
chr4:133843631-133958319:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
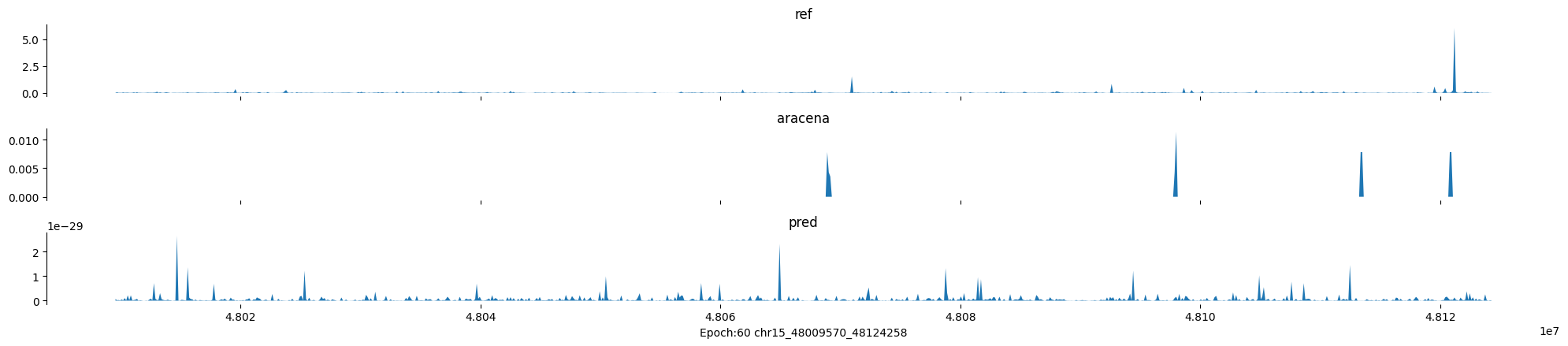
Epoch: 60
0
chr15:48009570-48124258:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
Epoch: 61
0
chr19:15542632-15657320:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
Epoch: 62
0
chr22:31219262-31333950:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
Epoch: 63
0
chr12:28860106-28974794:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
Epoch: 64
0
chr8:32497029-32611717:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
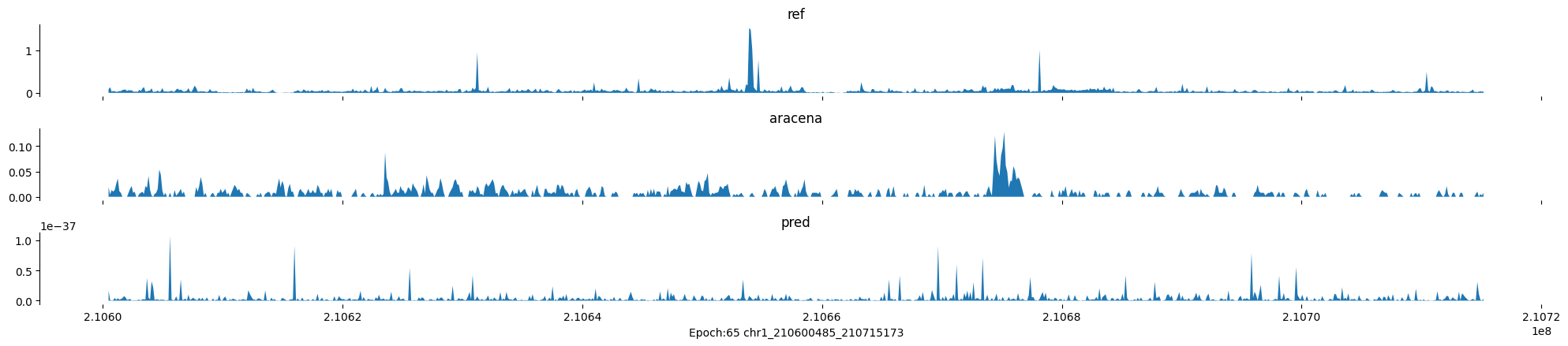
Epoch: 65
0
chr1:210600485-210715173:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
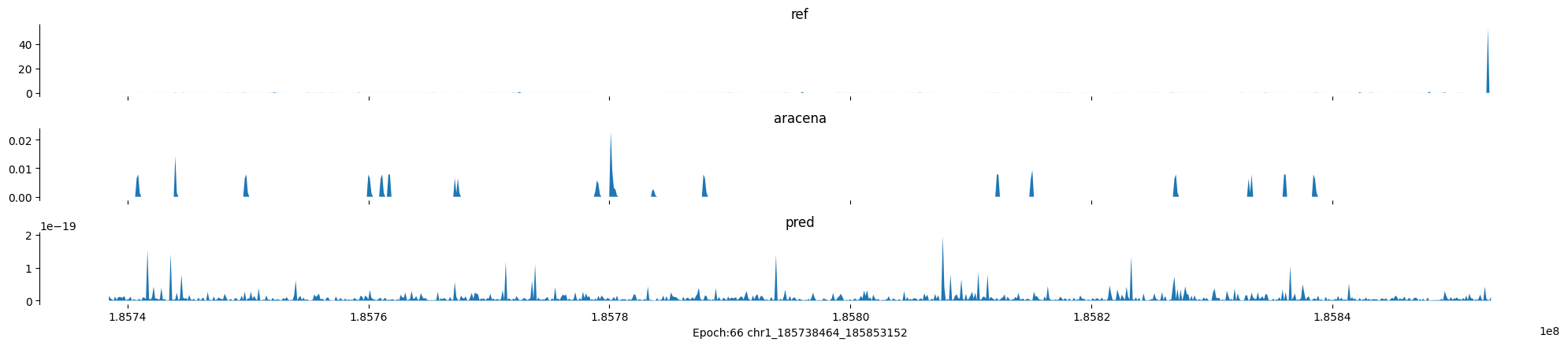
Epoch: 66
0
chr1:185738464-185853152:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
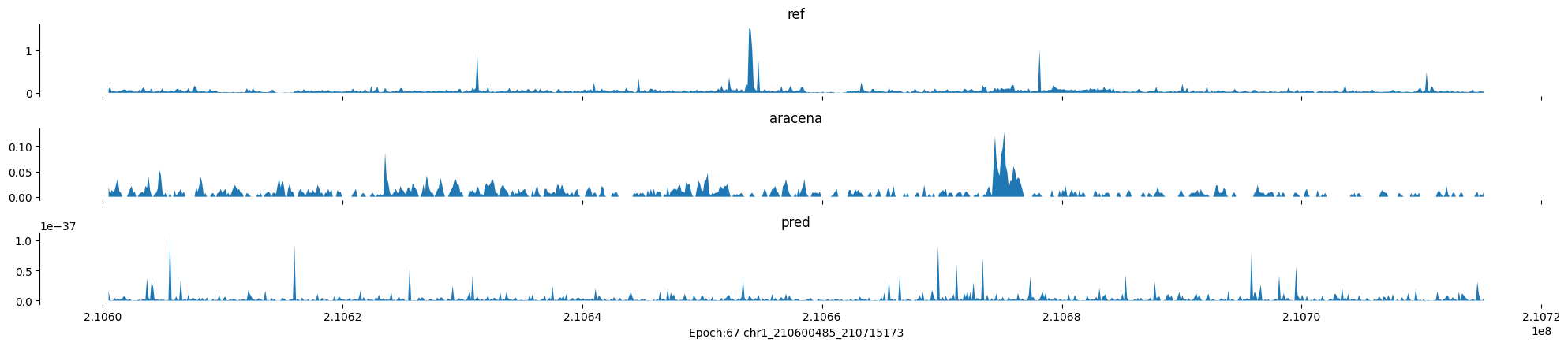
Epoch: 67
0
chr1:210600485-210715173:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
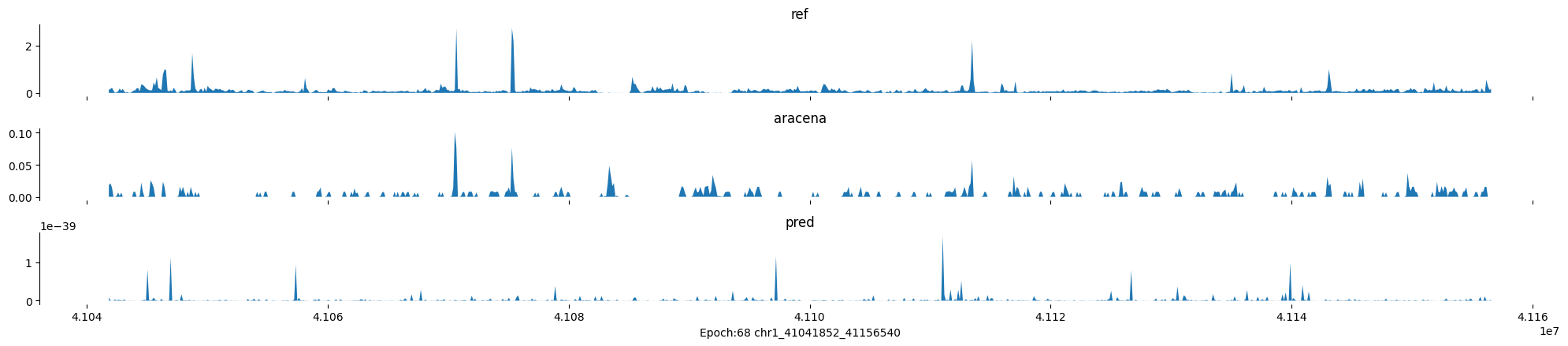
Epoch: 68
0
chr1:41041852-41156540:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
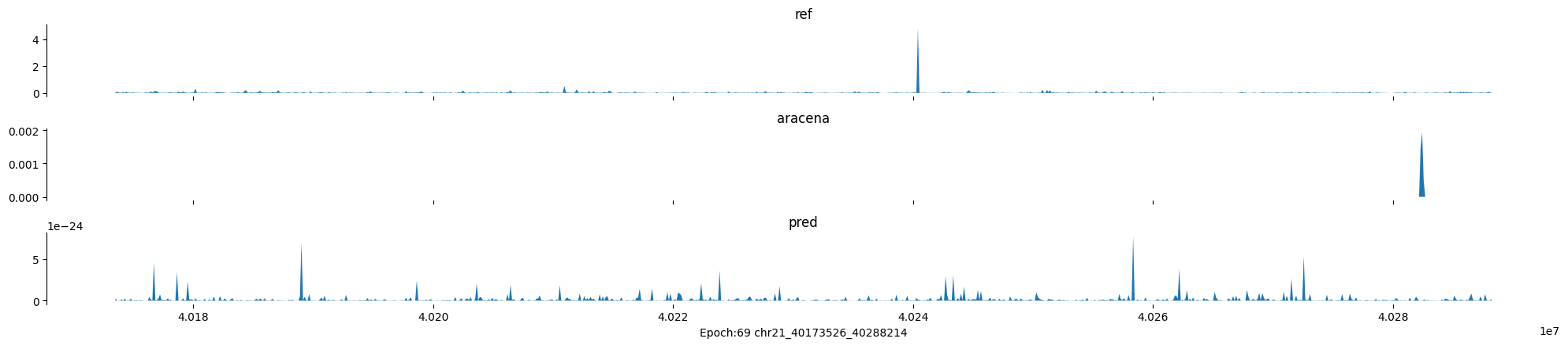
Epoch: 69
0
chr21:40173526-40288214:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
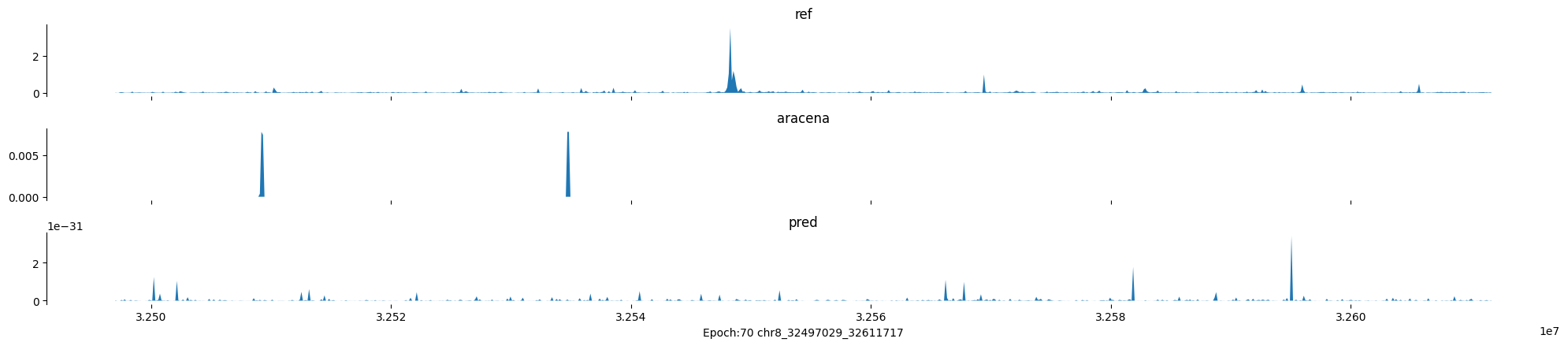
Epoch: 70
0
chr8:32497029-32611717:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
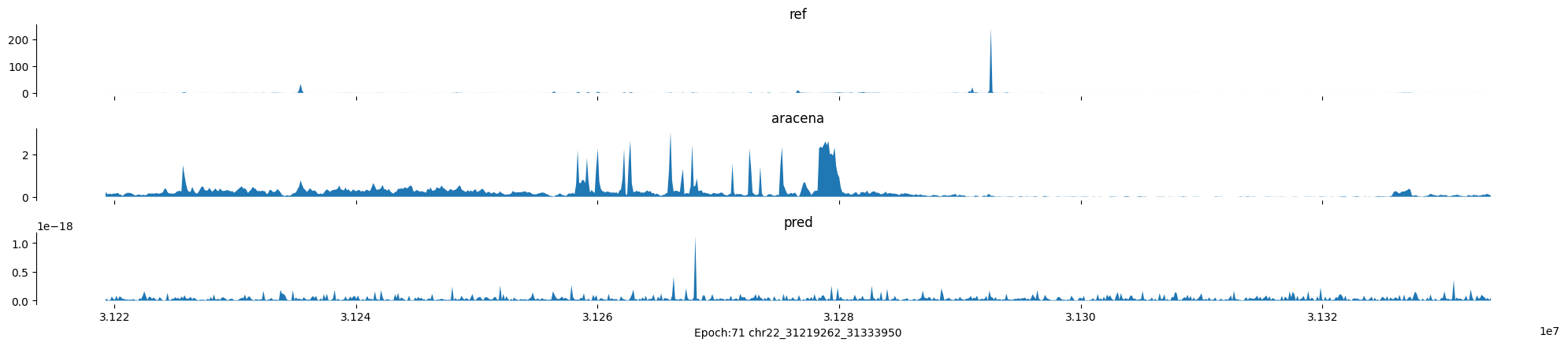
Epoch: 71
0
chr22:31219262-31333950:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
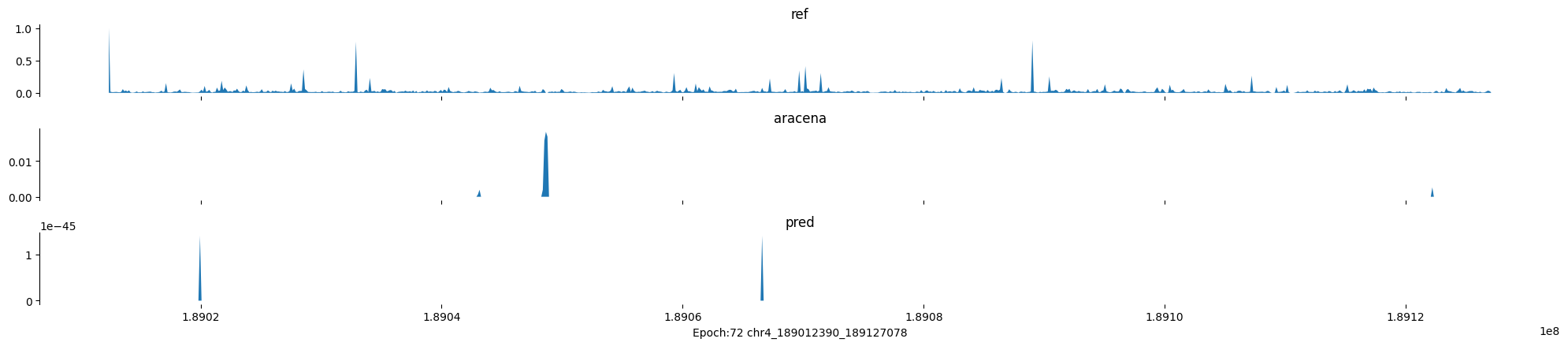
Epoch: 72
0
chr4:189012390-189127078:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
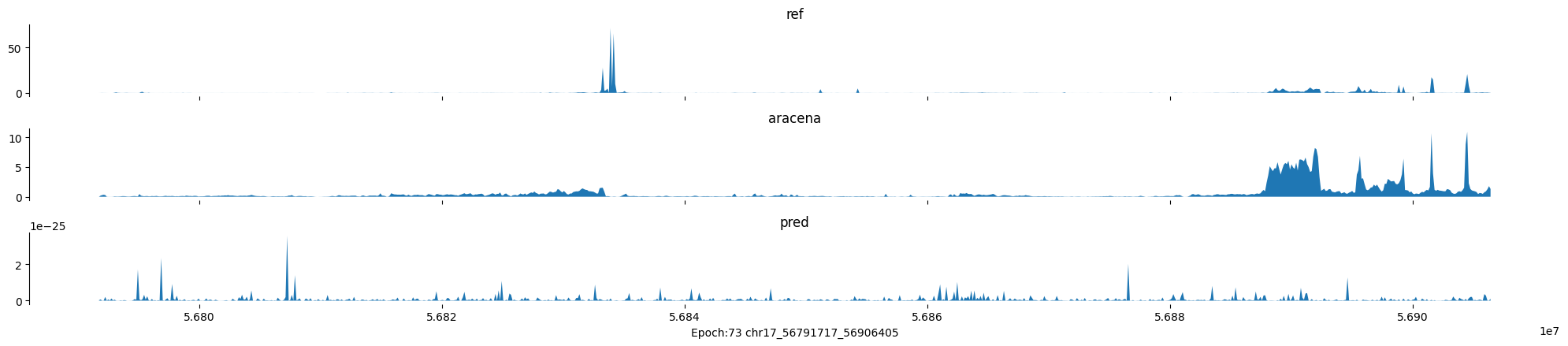
Epoch: 73
0
chr17:56791717-56906405:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
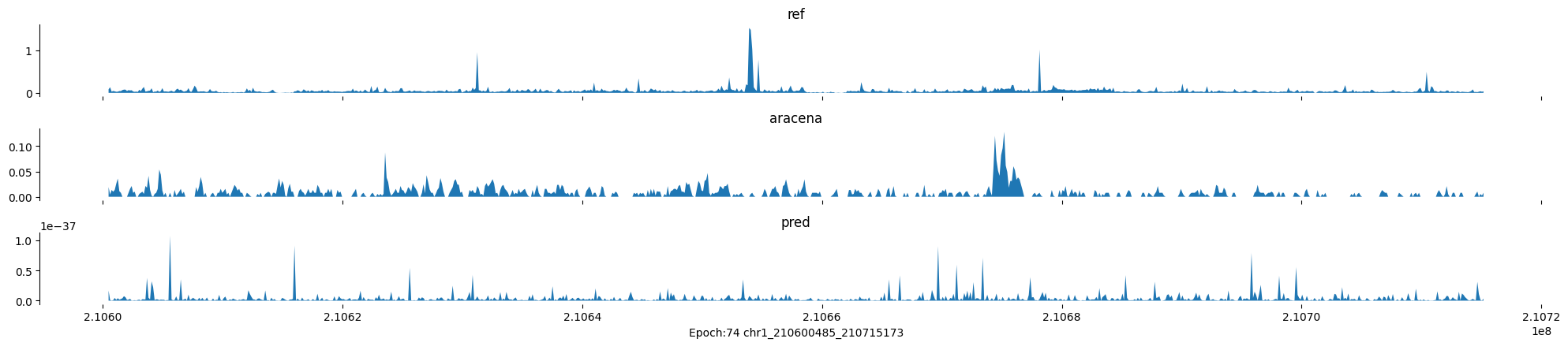
Epoch: 74
0
chr1:210600485-210715173:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
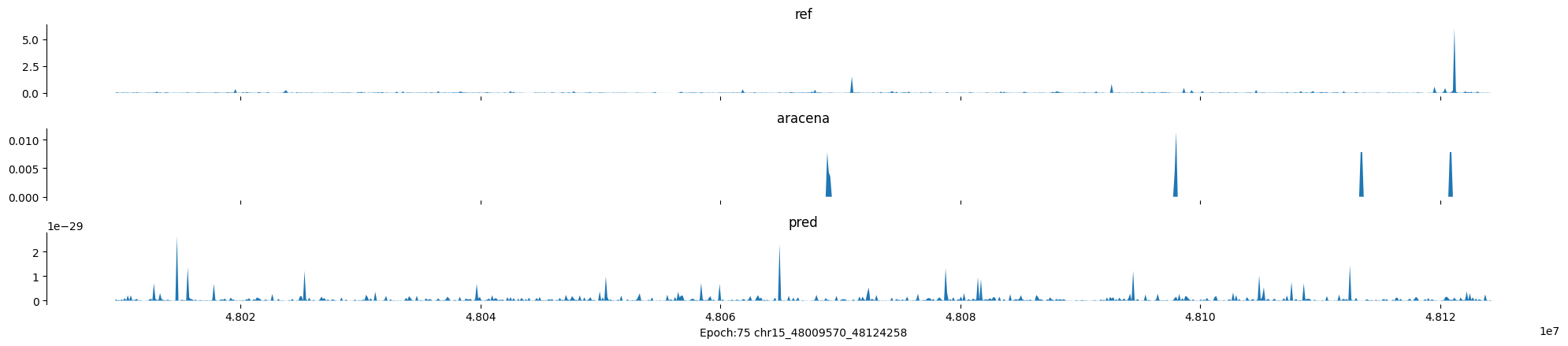
Epoch: 75
0
chr15:48009570-48124258:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
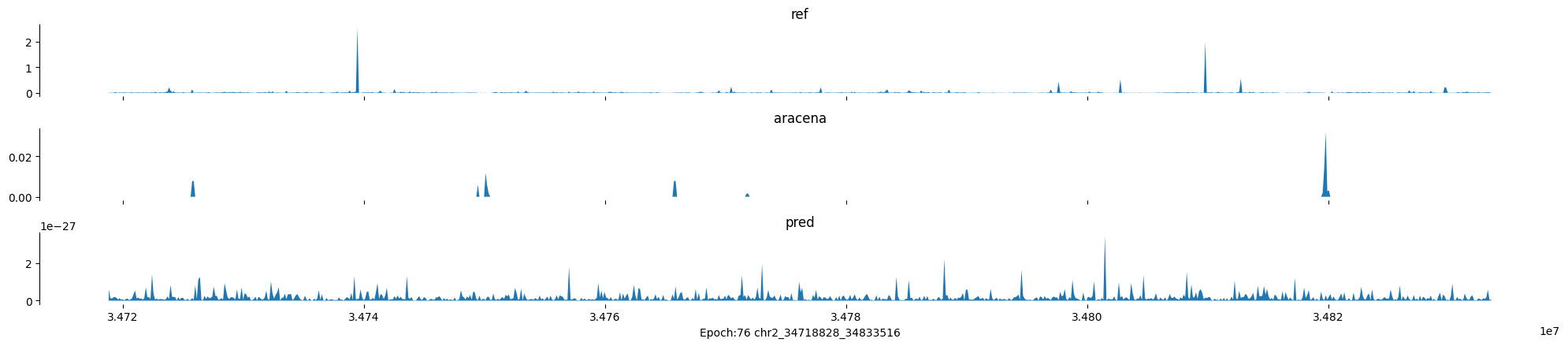
Epoch: 76
0
chr2:34718828-34833516:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
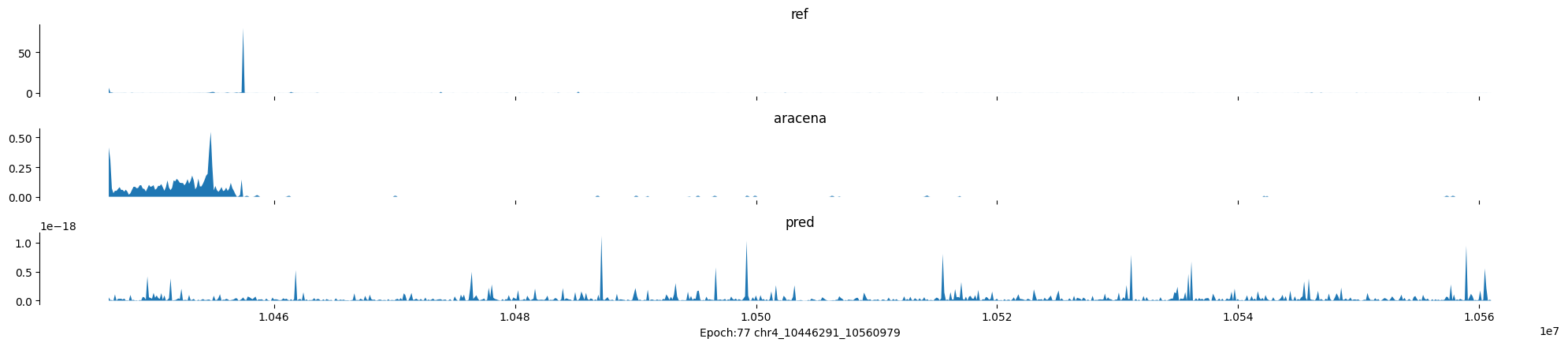
Epoch: 77
0
chr4:10446291-10560979:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
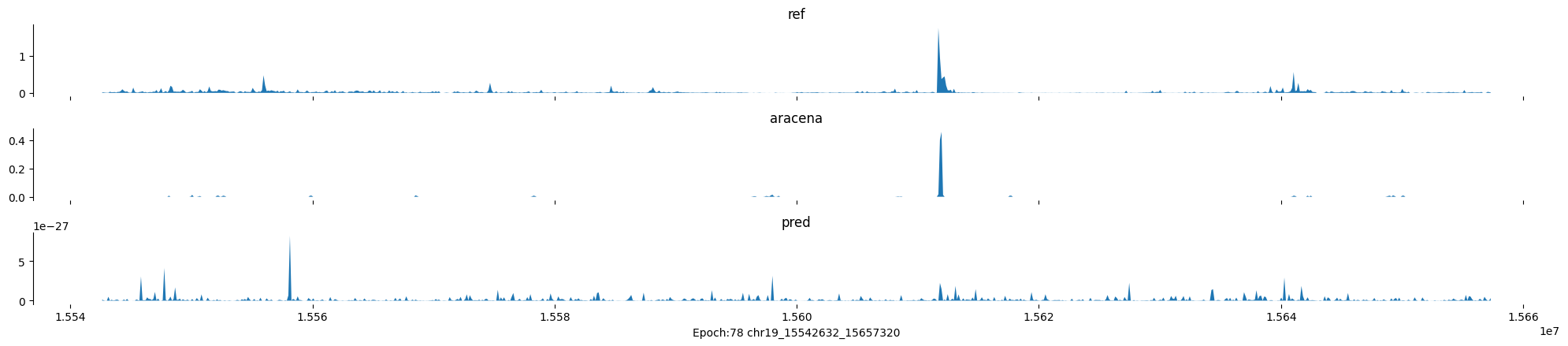
Epoch: 78
0
chr19:15542632-15657320:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
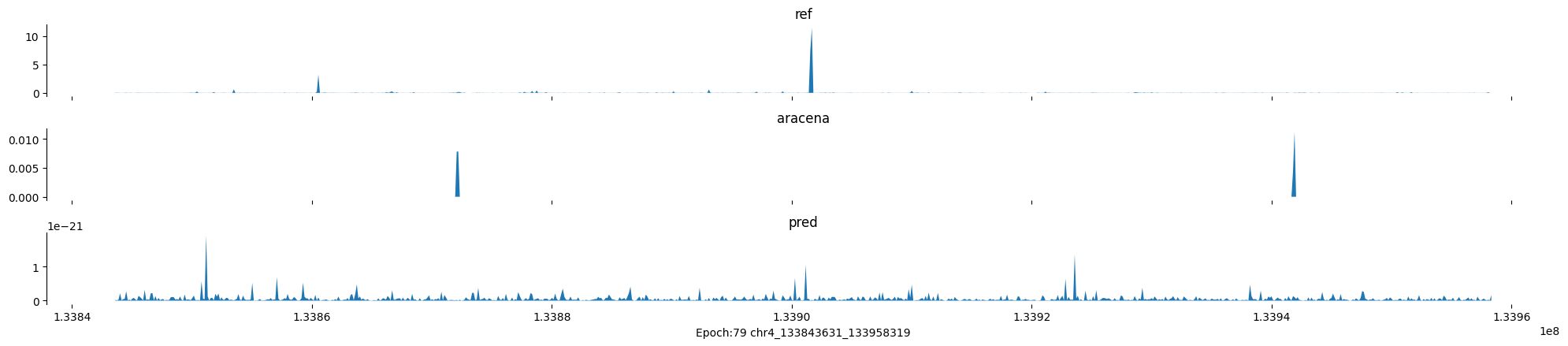
Epoch: 79
0
chr4:133843631-133958319:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
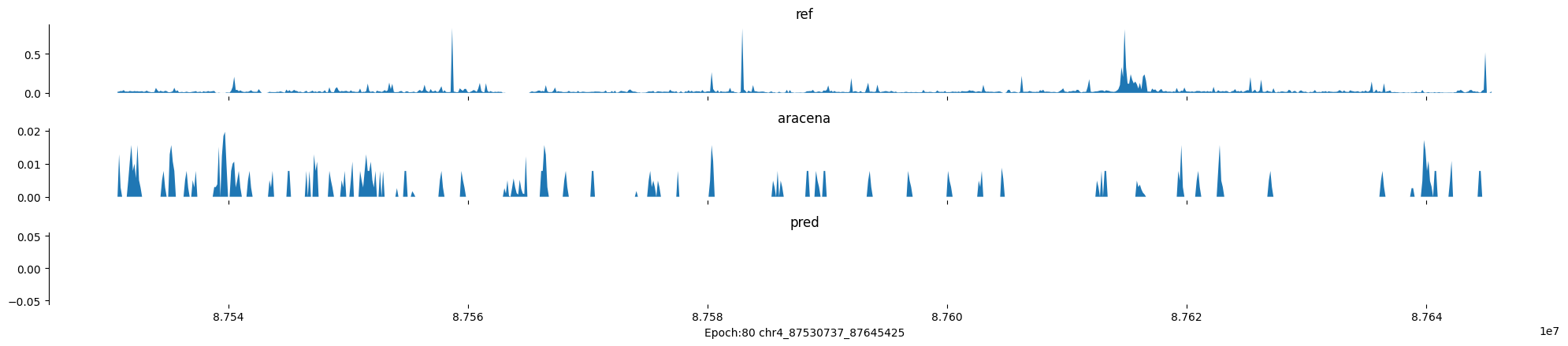
Epoch: 80
0
chr4:87530737-87645425:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
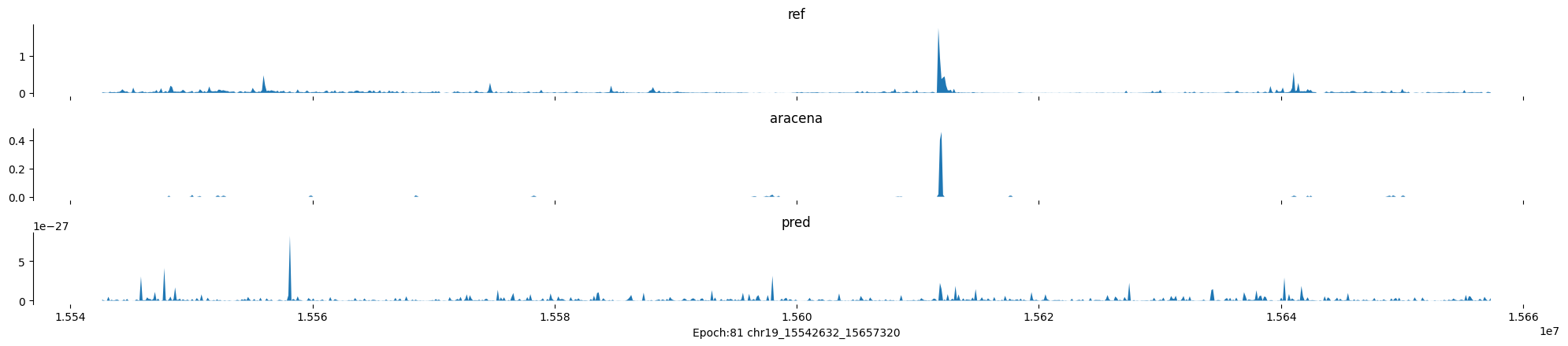
Epoch: 81
0
chr19:15542632-15657320:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
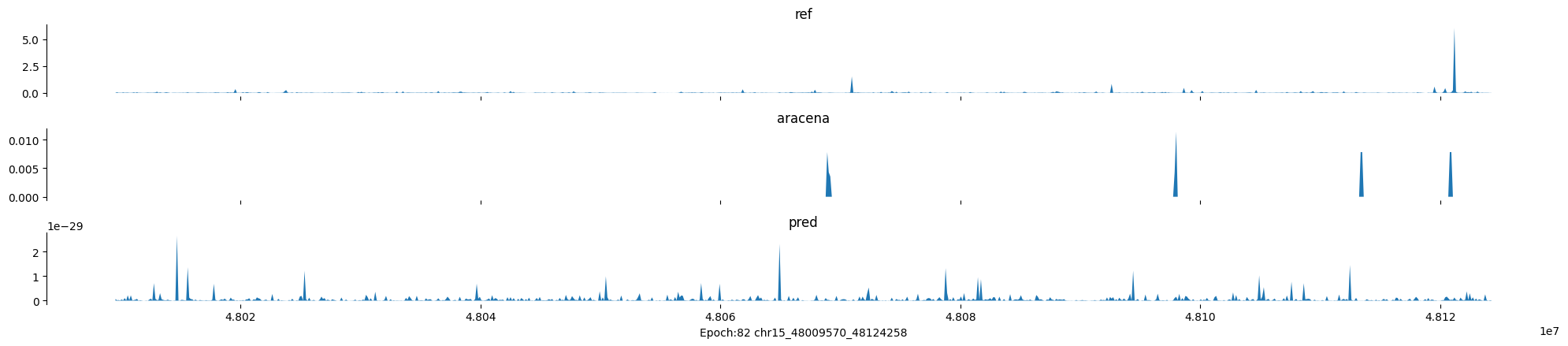
Epoch: 82
0
chr15:48009570-48124258:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
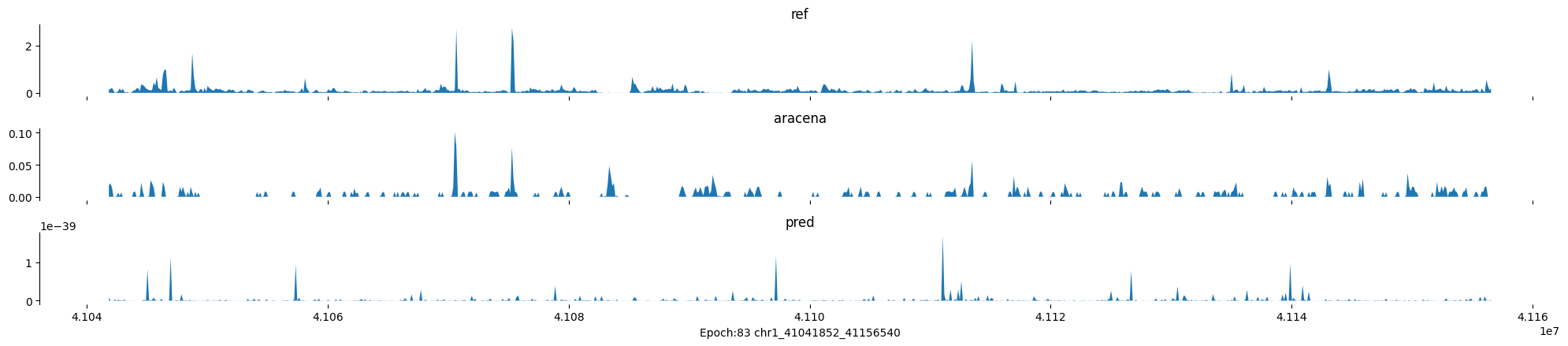
Epoch: 83
0
chr1:41041852-41156540:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
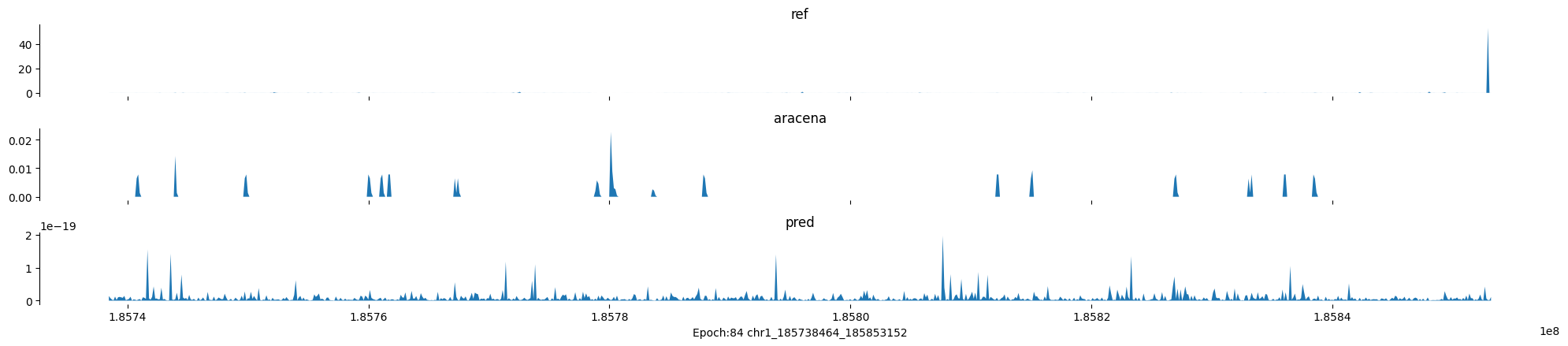
Epoch: 84
0
chr1:185738464-185853152:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
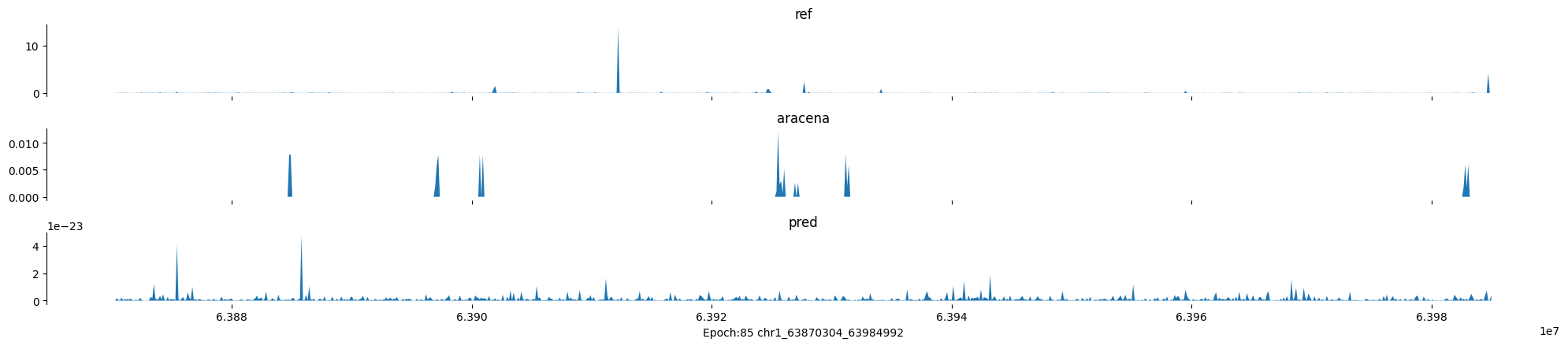
Epoch: 85
0
chr1:63870304-63984992:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
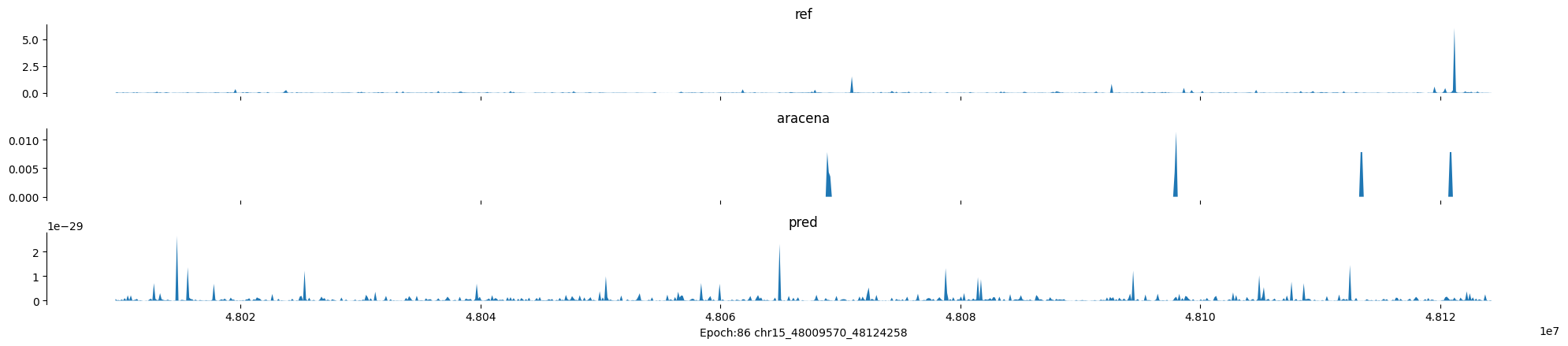
Epoch: 86
0
chr15:48009570-48124258:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
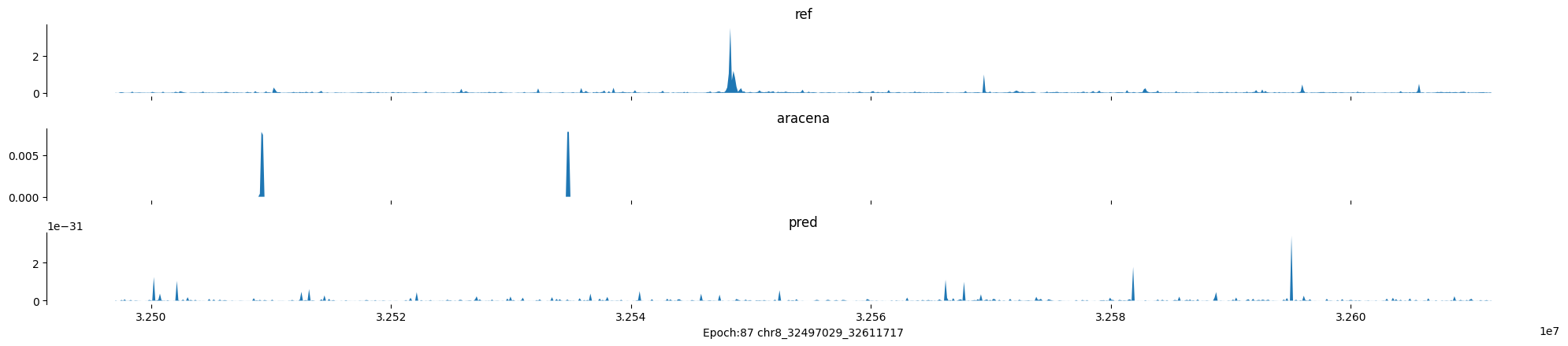
Epoch: 87
0
chr8:32497029-32611717:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
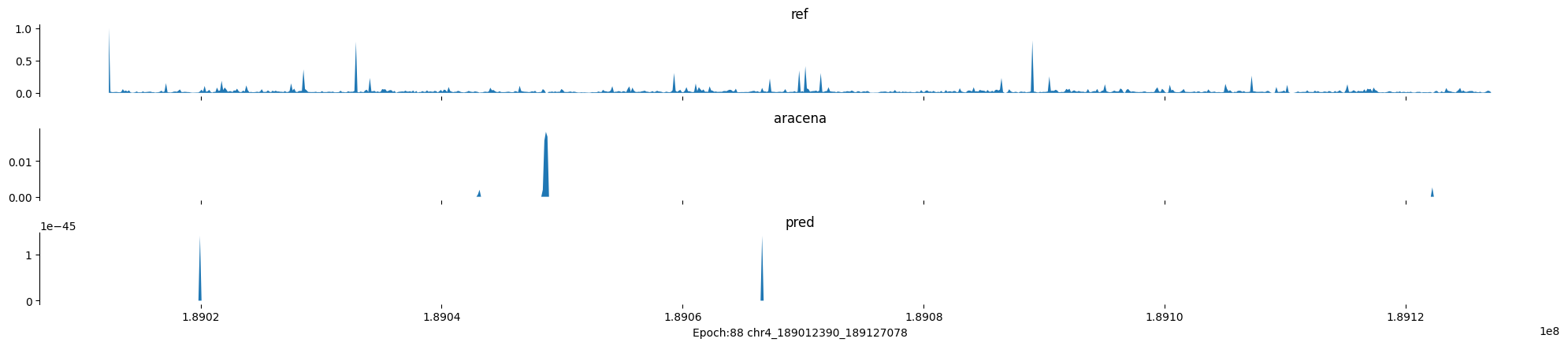
Epoch: 88
0
chr4:189012390-189127078:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
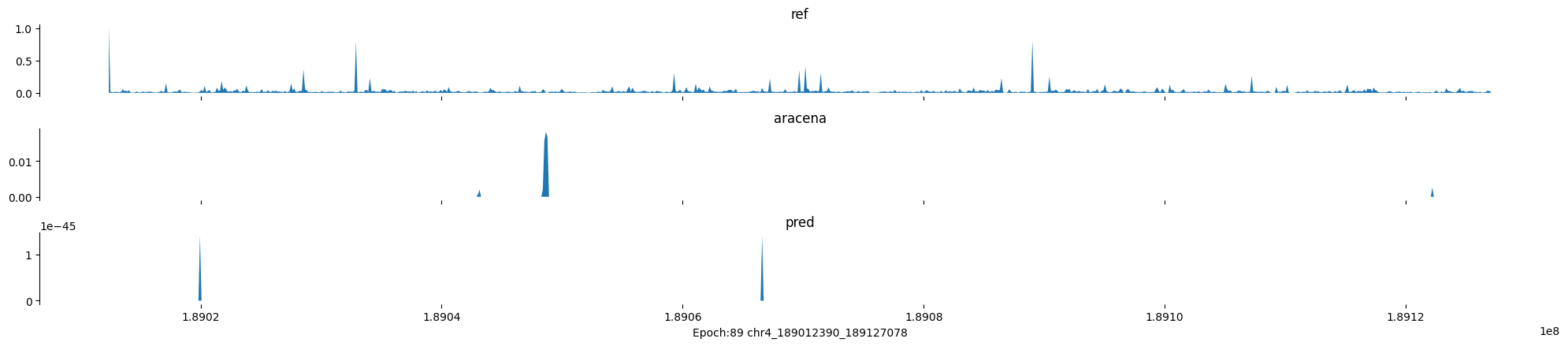
Epoch: 89
0
chr4:189012390-189127078:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
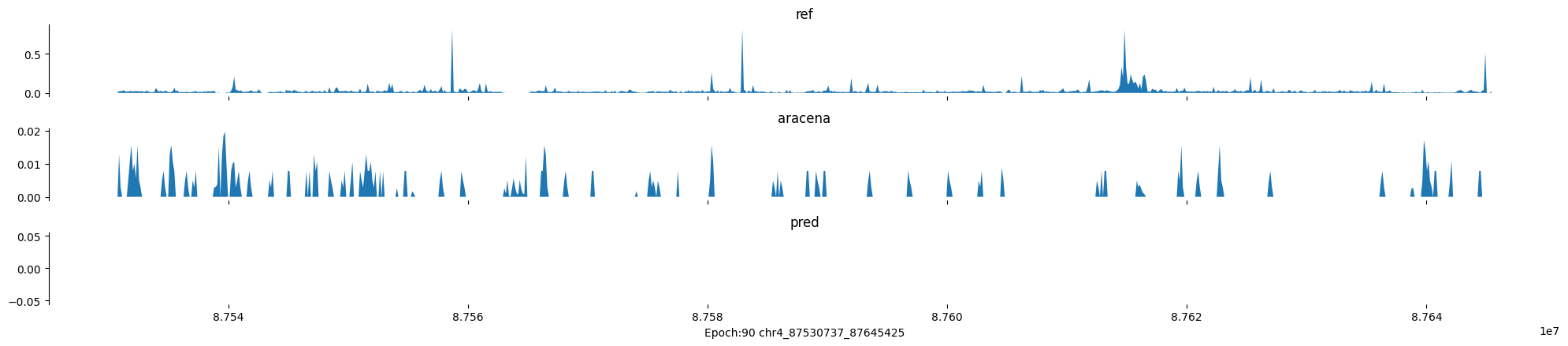
Epoch: 90
0
chr4:87530737-87645425:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
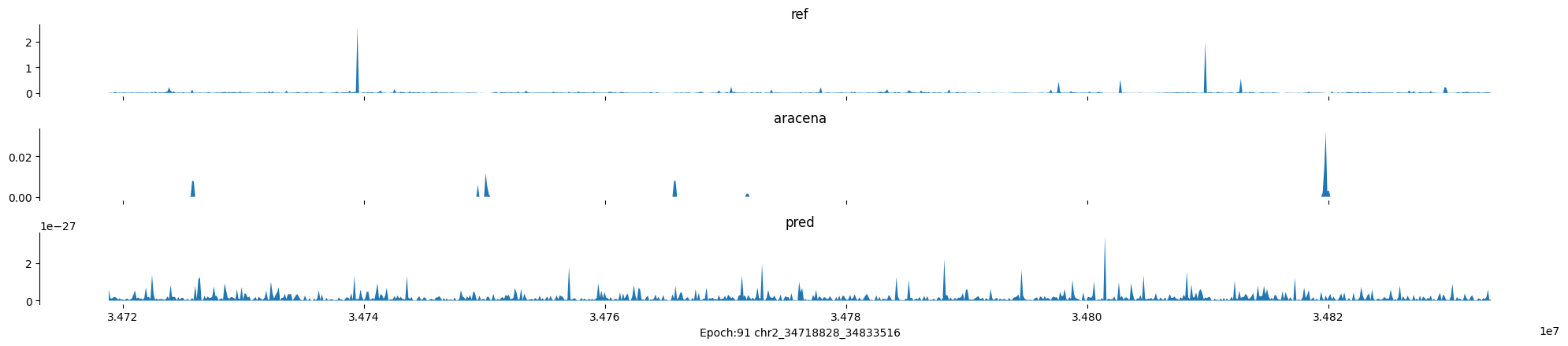
Epoch: 91
0
chr2:34718828-34833516:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
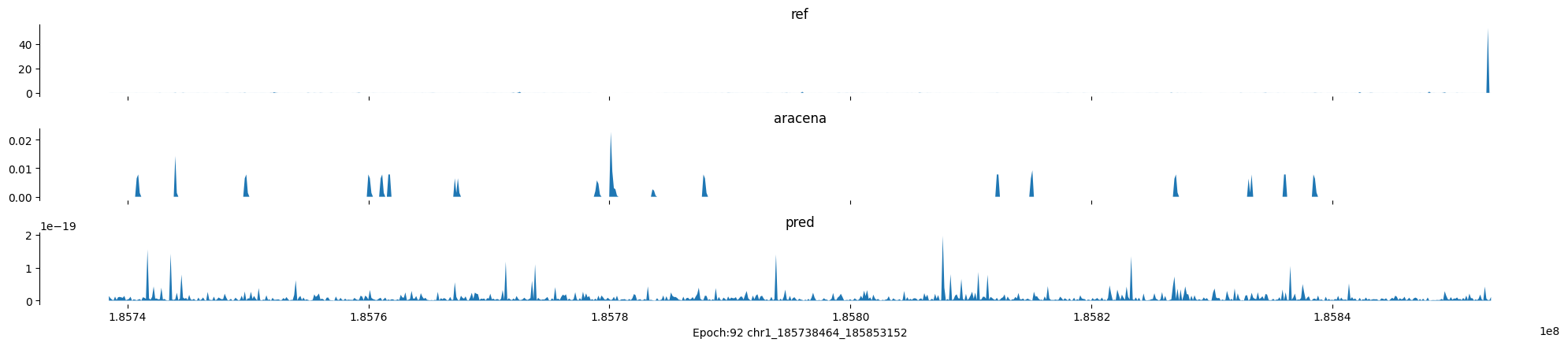
Epoch: 92
0
chr1:185738464-185853152:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
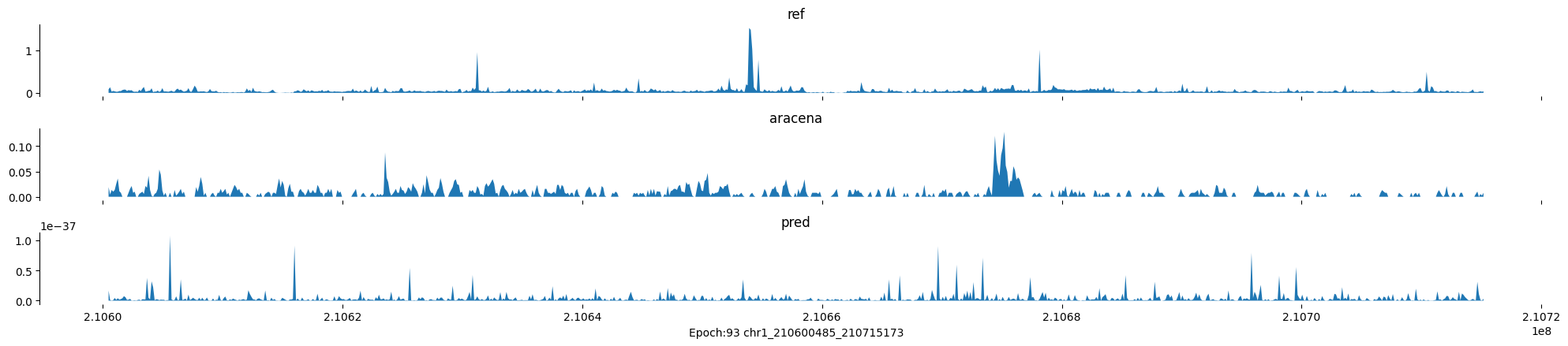
Epoch: 93
0
chr1:210600485-210715173:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
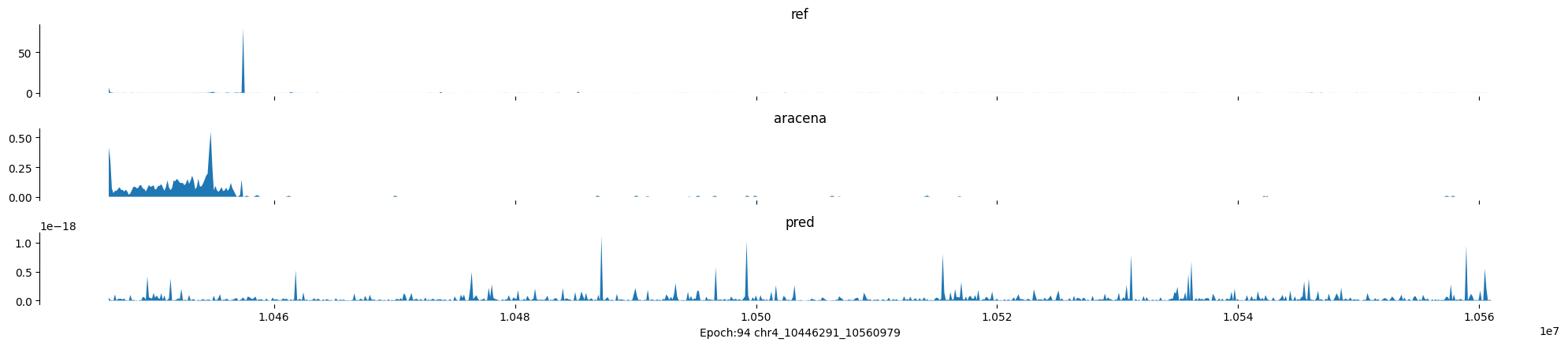
Epoch: 94
0
chr4:10446291-10560979:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
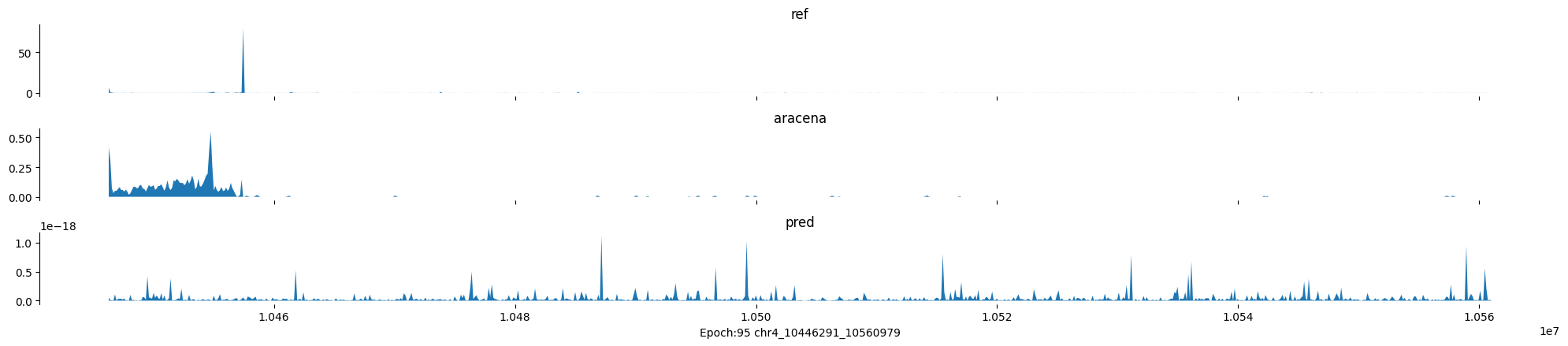
Epoch: 95
0
chr4:10446291-10560979:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
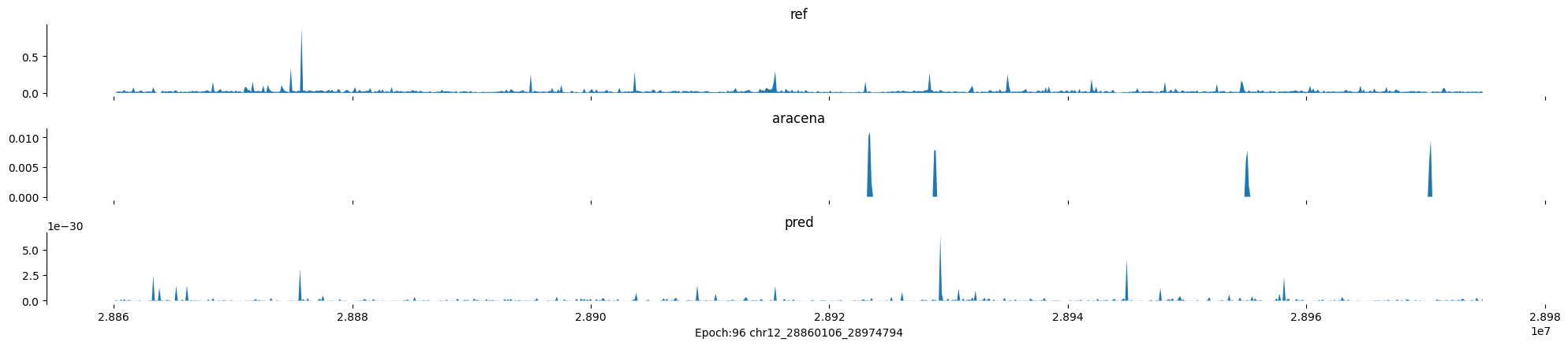
Epoch: 96
0
chr12:28860106-28974794:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
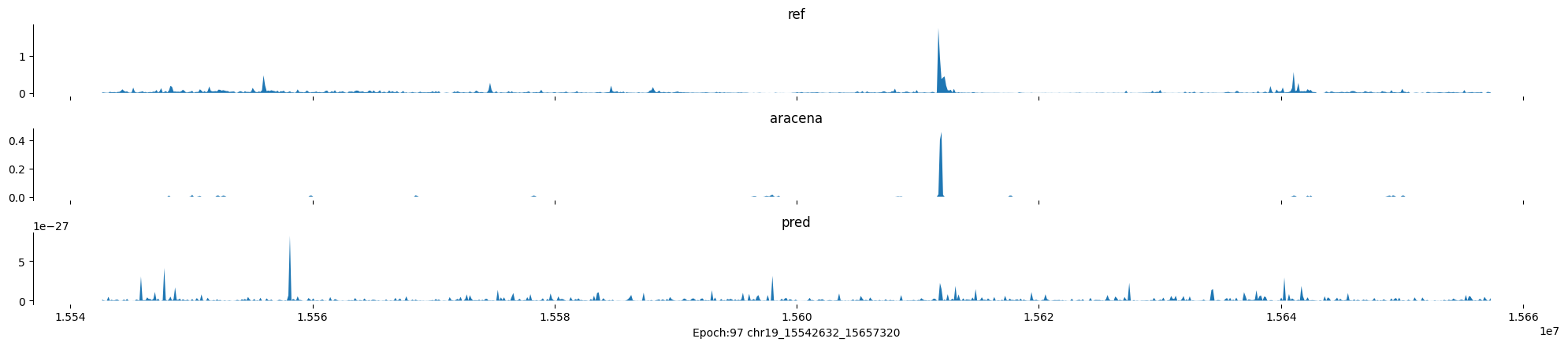
Epoch: 97
0
chr19:15542632-15657320:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
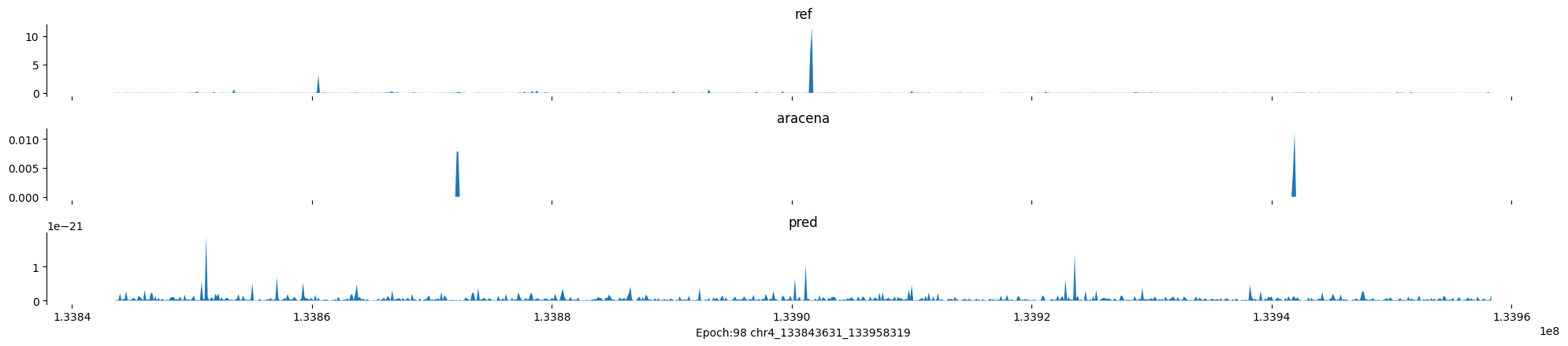
Epoch: 98
0
chr4:133843631-133958319:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])
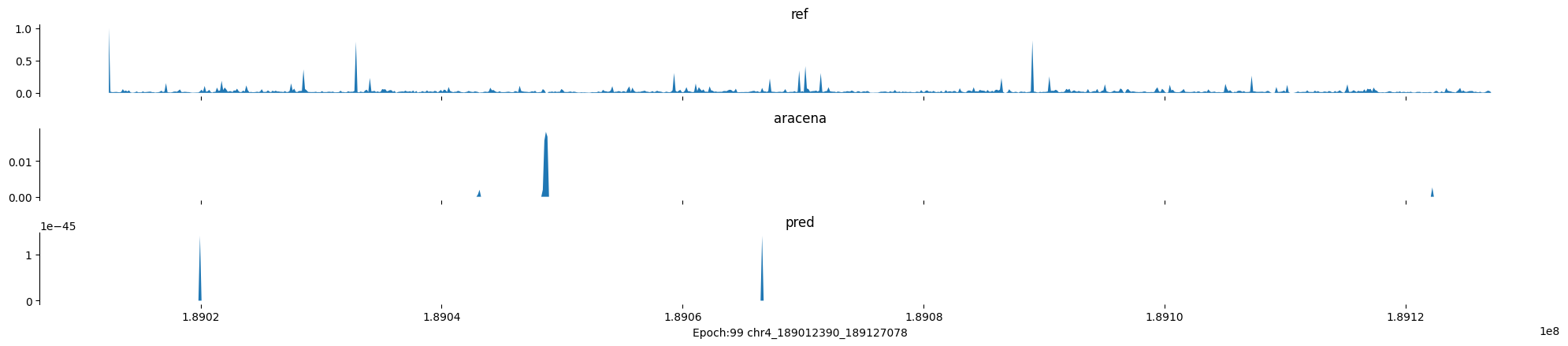
Epoch: 99
0
chr4:189012390-189127078:.
input shape torch.Size([1, 1, 896])
target shape torch.Size([1, 1, 896])
model_predictions shape torch.Size([1, 1, 896])